
Discover why live-researched B2B data outperforms static databases for modern marketing. Learn how real-time verified contact data improves targeting, email deliverability, campaign performance, and sales pipeline quality.
In the B2B marketing landscape, the gap between execution and outcomes is shifting. Revenue teams today are armed with incredibly sophisticated marketing automation stacks, advanced intent-data networks, and generative AI tools designed to personalize copy at unprecedented speed. Yet, despite these multi-million dollar tech investments, many Go-To-Market (GTM) motions are stalling out.
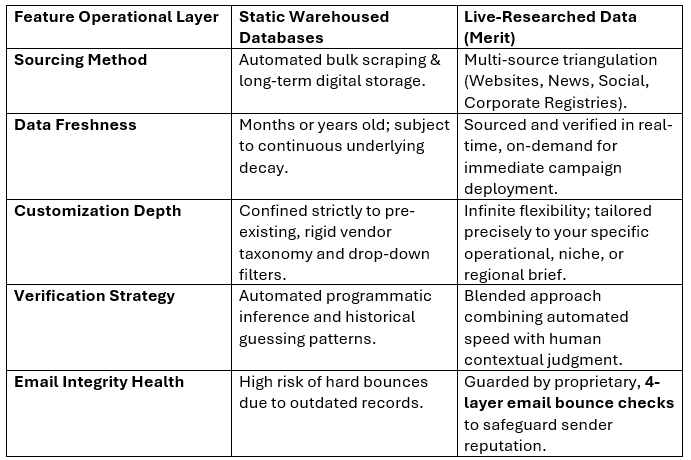
The bottleneck is not the creative, the messaging, or the software. It’s the infrastructure beneath it. Many cutting-edge strategies are still running on an incredibly fragile foundation: static, pre-packaged databases.
Traditional database models excel at giving teams broad market visibility and a solid starting point for wide-net discovery. However, because data decay is continuous, a gap naturally forms between the time data is stored and the time a campaign goes live. When execution relies entirely on older records, marketing teams frequently run into friction points that can impact budget efficiency and campaign momentum.
Relying on a static warehouse is not just an operational inefficiency; it is a direct threat to your campaign performance, your sales morale, and your corporate domain reputation. To win the inbox and scale high-value outbound motions, forward-thinking B2B marketing leaders are shifting away from stored data asset models and moving toward live-researched contact intelligence. Here is a comprehensive look at why live data has transitioned from a competitive advantage to a baseline survival requirement for modern marketing.
The fundamental, unfixable flaw of any static database is that it begins to obsolesce the exact second it is collected. The modern corporate landscape is highly volatile. People change employers, secure promotions, pivot to different departments, step into interim roles, and alter their strategic buying mandates daily.
Across the B2B sector, standard industry benchmarks reveal that contact databases degrade at a staggering rate of 22.5% to 30% every single year. For highly volatile sectors like technology, high-growth startups, or specialized engineering, that decay rate can climb even higher.
When you purchase a list from a traditional off-the-shelf data broker, you are paying top dollar for a historical snapshot. You are purchasing records that have likely been sitting dormant on a vendor's server for half a year. Attempting to fuel a precise Account-Based Marketing (ABM) campaign or an enterprise outbound sequence with these stale records guarantees that a massive portion of your marketing budget is burning up on ghost profiles and inactive inboxes.
The vast majority of static database vendors are simply repackaging a single source: LinkedIn. While it remains a powerful discovery tool, it relies entirely on voluntary, manual user updates.
The baseline rules of email delivery have permanently hardened. Major email providers utilize incredibly strict, automated behavioral filters to protect corporate ecosystems.
If your outbound campaign’s hard bounce rate creeps past 2% to 5%, your corporate sending domain is immediately flagged as a bad actor. Static databases are inherently riddled with dead domains and obsolete emails.
Uploading a bulk, pre-packaged list directly into your marketing automation system can cause a sudden spike in bounces, landing your primary domain on global blacklists and effectively silencing your entire outbound sales development team.
Traditional databases categorize prospects using incredibly rigid, surface-level criteria: Geography, Employee Count, and Job Title Keywords. But modern B2B buying committees are matrixed and highly cross-functional.
A "Director of Operations" at a 500-person SaaS firm has a fundamentally different mandate, budget, and pain point than a "Director of Operations" at a 500-person regional medical manufacturing plant.
Static data flattens this context, leading to generic targeting that falls flat with the buyer.
If you bought your list from a traditional bulk vendor, your direct competitors are likely calling, emailing, and targeting the exact same records with the exact same filters.
This dynamic floods the inboxes of easily accessible prospects, causing severe ad-fatigue, skyrocketing cost-per-acquisition (CPA), and rock-bottom response rates.
Live-researched data completely flips this commodity model on its head.
At Merit Data & Technology, our database size is exactly zero. We don't warehouse data because we treat contact intelligence as a dynamic, real-time service rather than a static product.
When you share your unique Ideal Customer Profile (ICP) and campaign criteria with us, your contacts aren't pulled out of an existing bucket. They are discovered, mapped, and verified live, from scratch, across multiple credible sources specifically to answer your brief.
A Side-by-Side Architectural Comparison
Building highly effective, campaign-ready B2B lists is not about choosing between automated scale and human accuracy - it’s about architecting a workflow where they complement one another.
Advanced automation sweeps the broader web, localized company directories, press releases, corporate restructuring announcements, and digital footprints. This rapid data aggregation ensures that any recent organizational shifts, funding rounds, or leadership changes are caught in real time.
Once the automated systems surface the target accounts and profiles, highly trained human data specialists step in to perform the critical quality control that algorithms simply cannot replicate. They evaluate actual role responsibility over mere titles, reconcile conflicting professional signals across different platforms, and manually clean the formatting.
This human touch ensures that your data enters your CRM entirely immaculate. There are no lowercase names, no messy corporate legal suffixes (like LLC or Inc.) embedded in company names, and no formatting errors.
It is 100% CRM-ready, meaning your marketing operations team can skip the manual spreadsheet parsing and move straight to launching campaigns.
In B2B marketing, chasing raw database volume is a vanity play that yields diminishing returns. Possessing a list of 50,000 generic contacts means nothing if a quarter of them have left the company, another third bounce, and the rest lack actual purchasing authority.
Real market differentiation belongs to the teams that target the exact buyers their competitors are entirely missing.
By breaking away from static databases and embedding a live-researched data framework into your GTM stack, you clear the operational friction holding your revenue teams back.
Your sales reps stop hitting dead ends, your marketing team stops stressing over domain reputation, and your campaigns run on pure, actionable intelligence.
If you are currently deploying high-investment Account-Based Marketing (ABM) plays, trying to scale personalized outbound pipelines, or penetrating highly specialized, niche global markets, you cannot afford to rely on whatever a vendor happens to have stored on file.
Whether you need to validate and revive an old, decaying CRM database, uncover hidden target companies matching an ultra-specific ICP, or find new decision-makers outside of standard social platforms, your data should be custom-built for your business.
Ultimately, a robust GTM strategy requires a data foundation that matches the agility of your marketing and sales teams. While broad-scale databases remain a valuable asset for top-of-funnel discovery and market mapping, high-value outreach requires data that teams can trust implicitly from day one.
By integrating a live-researched data framework into your revenue operations, you reduce the friction between marketing data and sales execution. When lists are verified in real time to match exact account criteria, sales cycles shorten, deliverability rates remain secure, and marketing spend translates into measurable pipeline impact.
Success in 2026 is defined less by the absolute volume of contacts accumulated, and more by the data confidence that empowers teams to execute seamlessly.