
This second part goes from theory to architecture. It details clause‑as‑entity data models, clause metadata, jurisdiction‑aware taxonomies, graph‑RAG, and hybrid relational–graph stores, showing how to build clause‑level contract intelligence pipelines that deliver deterministic, auditable legal decisions instead of brittle, chunk‑based RAG answers.
In Part 1, we saw why standard, chunk‑based RAG and generic ChatGPT‑style copilots cannot satisfy the zero‑error tolerance and traceability requirements of legal, advisory, and compliance work.They fragment context, ignore document hierarchy, and treat clauses as isolated strings, which is precisely how you end up with AI systems that retrieve the “right” clause but apply the wrong meaning.
Part 2 is about the remedy, not the diagnosis. The core claim is simple: the failure is a data‑modelling problem, and the fix is a clause‑centric data model. Instead of treating a contract as a file to be searched, we treat each clause as a first‑class data entity with its own ID, metadata, version history, and graph of relationships to definitions, carve‑outs, schedules, and external regulations.
On top of that structure, we can finally build deterministic policy engines, graph‑aware retrieval, and carefully constrained generative assistants that are reliable enough for high‑stakes decisions. The sections that follow walk through this architecture in detail: how to model clauses as entities, how to design clause metadata and taxonomies, how to build an ingestion and extraction pipeline that preserves legal structure, and how to layer hybrid deterministic generative AI on top so that every answer can be traced back to specific source text that will stand up to regulatory and courtroom scrutiny.
The key architectural shift is not cosmetic. Moving from a document‑centric to a clause‑centric model means changing what the primary data entity is. In a document‑centric system, the file is the record. Everything else clause text, party names, dates, obligations is content within that record, readable only by parsing the file. Delete or replace the file, and the data is gone.
In a clause‑centric model, the clause is the record. The file it originated from is a source reference, not a container. This distinction has precise engineering consequences:
Each clause must have its own independent lifecycle. A clause is created when first extracted, modified when negotiated, superseded when amended, and archived when the contract expires and each of these state transitions must be tracked independently of what happens to the source document. If the original PDF is replaced by a redlined version, the clause record must not be overwritten. It must be versioned, with the new text creating a new clause version linked to the original by a SUPERSEDES relationship, and the old version retained with its valid_to timestamp set.
Each clause must have its own versioning chain. In practice, a single commercial contract over a five-year term may accumulate three amendments, two side letters, and a novation. Each of these events modifies specific clauses. A clause‑centric model tracks this as a version graph:
Clause#1247 (original, valid 2019-01-01 to 2021-06-30)
└── SUPERSEDED_BY Clause#1247v2 (Amendment 1, valid 2021-07-01 to 2023-03-14)
└── SUPERSEDED_BY Clause#1247v3 (Amendment 3, valid 2023-03-15 to present)
A query asking "what were our indemnity obligations under this contract as of 1 January 2022?" retrieves Clause#1247v2 — not by searching document text, but by traversing the version graph with a date filter. That operation is impossible in a document-centric or chunk-based system, because neither models clause identity across file versions.
Each clause must have its own metadata, independent of document-level metadata. Document-level metadata — contract type, counterparty, execution date — describes the agreement as a whole. Clause-level metadata describes the specific provision: its canonical type, risk score, jurisdiction applicability, extraction confidence, playbook deviation flag, and the identity of the reviewer who validated it. This metadata persists and evolves independently. A clause can be reclassified from "standard" to "non-standard" following a regulatory change, without any modification to the source document, because the classification lives on the clause entity, not in the file.
Each clause must be queryable without reference to its source file. Once extracted and modelled, a clause entity is a first-class database record. It can be joined against obligation tables, filtered by jurisdiction metadata, aggregated into portfolio risk reports, and surfaced in matter management workflows — none of which require the original document to be opened, parsed, or present in the system. The clause has escaped the document. That is the architectural goal.
In the clause‑as‑entity model, the system explicitly represents:
A logical schema for a clause‑centric model in a professional services context may include:
Here is a minimal relational schema that treats clauses as first‑class entities in the contract data model:
-- Core contract table
CREATE TABLE contracts (
id UUID PRIMARY KEY,
type VARCHAR(50) NOT NULL,
client_id UUID NOT NULL,
counterparty_id UUID NOT NULL,
effective_date DATE NOT NULL,
expiry_date DATE,
jurisdiction VARCHAR(50) NOT NULL,
governing_law VARCHAR(100),
status VARCHAR(30) NOT NULL,
source_system VARCHAR(100),
version_id UUID,
parent_contract_id UUID
);
-- Clause as a first-class entity
CREATE TABLE clauses (
id UUID PRIMARY KEY,
contract_id UUID NOT NULL REFERENCES contracts(id),
clause_number VARCHAR(50),
title VARCHAR(255),
canonical_type VARCHAR(100), -- e.g. LIABILITY_LIMITATION,
DPA, IP_OWNERSHIP
text TEXT NOT NULL,
section_path VARCHAR(255), -- e.g. '3.2.1/Indemnity/Third-Party Claims' source_page_from INT,
source_page_to INT,
is_standard BOOLEAN,
risk_score NUMERIC(5,2),
version_id UUID
);
-- Simple key/value metadata for clauses
CREATE TABLE clause_metadata (
id UUID PRIMARY KEY,
clause_id UUID NOT NULL REFERENCES clauses(id),
key VARCHAR(100) NOT NULL,
value VARCHAR(500),
value_type VARCHAR(50), -- STRING, NUMBER, DATE, BOOLEAN
extraction_method VARCHAR(50), -- RULE, MODEL, MANUAL confidence NUMERIC(5,2), normalized_flag BOOLEAN DEFAULT FALSE );
This logical model can be implemented in:
Metadata is the mechanism that converts probabilistic AI output into deterministic system behaviour. Without it, every compliance check, every risk flag, and every policy enforcement decision depends on a prompt and a prompt is not a policy. It is a request. Requests can be misinterpreted, inconsistently applied, and silently wrong in ways that leave no audit trail.
The architectural division of responsibility in a clause-centric intelligence system is precise:
The LLM handles extraction. Metadata handles enforcement.
The language model's job is to read clause text and populate structured fields: identify the canonical clause type, extract the liability cap amount, flag the governing law, detect the presence or absence of a mutual indemnity carve-out. This is a task where probabilistic language understanding is appropriate and well-suited. The LLM is good at reading legal text and converting it into structured attributes.
Once those attributes exist as metadata fields on a clause entity, the LLM steps back entirely. Policy enforcement, compliance checks, risk scoring, and approval routing are now executed as SQL queries and rule engine evaluations against structured data not as prompts sent to a language model asking it to "check if this contract is compliant."
The difference is not subtle. Consider a firm-wide policy: "No contract may be executed if it contains an uncapped indemnity obligation and the counterparty is not on the approved vendor list." Enforcing this via prompt means asking an LLM to read the contract, interpret the indemnity clause, assess whether it is capped, cross-reference a vendor list, and return a yes/no decision every time, with no guarantee of consistency, and no audit trail of the reasoning. Enforcing this via metadata means running:
SELECT
c.id AS contract_id,
c.counterparty_id,
cl.canonical_type, AS liability_cap,
cm_cap.value AS liability_cap,
v.approved_flag AS vendor_approved
FROM contracts c
JOIN clauses cl
ON cl.contract_id = c.id
AND cl.canonical_type = 'INDEMNITY'
JOIN clause_metadata cm_cap
ON cm_cap.clause_id = cl.id
AND cm_cap.key = 'liability_cap.normalized'
AND cm_cap.value = 'UNLIMITED'
LEFT JOIN vendors v
ON v.id = c.counterparty_id
WHERE
(v.approved_flag IS NULL OR v.approved_flag = FALSE);
This query is deterministic, repeatable, auditable, and explainable. It produces the same result every time it runs. It generates an audit log that shows exactly which clause record, which metadata field, and which vendor record triggered the flag. It does not hallucinate. It does not misinterpret. It does not have a bad day.
This is what metadata enables and it is what prompts categorically cannot provide at the enforcement layer.
Clause metadata dimensions that drive these deterministic checks include:
The last dimension extraction provenance is particularly important. A metadata field extracted by a rule-based parser with deterministic logic can be trusted immediately for policy enforcement. A field extracted by an LLM with a confidence score of 0.73 should route to human review before it gates an approval decision. The metadata schema itself encodes this trust hierarchy, ensuring that the system knows which of its own outputs are reliable enough to act on deterministically and which are not.
One of the most persistent pain points in professional services is interpretive drift the same clause type negotiated differently by different partners, offices, or practice teams because there is no shared computational understanding of what "acceptable" looks like. General-purpose models like ChatGPT may "know the law" in a broad sense, but they do not know your firm’s specific risk posture, playbook tolerances, or red lines. That knowledge lives in precedent, partner judgment, and internal policies not in the public internet.
Architecture is how that institutional memory is encoded into the system. A clause-centric data model, enriched with legal ontologies and jurisdiction-aware playbooks, turns the firm’s risk posture into structured metadata and rules that apply consistently everywhere: the same indemnity clause is classified with the same canonical type, the same deviation label, and the same escalation requirement whether it appears in London, Singapore, or New York. In other words, we are not just using AI to read text; we are using AI to populate a data model that enforces a specific, standardised interpretation of clauses across the entire organisation, so the system reflects the firm’s view of risk not the model’s.
Without a structured interpretation layer, AI copilots amplify rather than resolve inconsistency:
The result is an AI system that reflects the inconsistency of its training corpus rather than enforcing firm‑level standards. In a large firm, this interpretive drift is not just a stylistic difference it is a structural risk: when different teams negotiate the same point differently, the firm loses the ability to understand and manage its aggregate risk posture. A clause‑centric, structured data model acts as a governance layer that forces consistency through a shared set of canonical types, playbook positions, and risk labels, ensuring every lawyer and every AI workflow is effectively working from the same playbook.
The architectural fix is a canonical clause taxonomy a firm-defined master list of clause types, sub-types, risk positions, and acceptable variations implemented as a structured ontology that all extraction and classification models are anchored to.
Key components include:
A clause‑centric data model naturally enables precedent linking connecting newly extracted clauses to prior negotiated positions across matters. This capability is only possible when contract data is structured at the clause level from the start, so that every negotiated position becomes a discrete, searchable data point rather than a line buried in a PDF.
When a clause is classified as canonical type IP > Ownership > Work for Hire, the system can:
This turns every negotiated deal into institutional memory that informs the next one, compounding interpretive consistency over time. Crucially, that memory is encoded in the data model, not just in partner experience, so AI systems inherit the same interpretation rules that humans applied in past matters. Platforms implementing this approach report up to 40% improvement in workflow efficiency and 60% faster contract review cycles compared to document-by-document review.
At the pipeline level, jurisdiction-aware interpretation standardisation requires several specific design choices. Jurisdiction must be treated as a global variable that changes the logic of the entire extraction pipeline, not just a tag added at the end. A data transfer clause governed by EU law is a different legal entity than a textually similar clause governed by Indian law, because the underlying regulatory regimes, permitted mechanisms, and enforcement risks are different even when the words are not.
The combined effect of canonical taxonomies, jurisdiction-aware ontologies, and precedent linking is that the firm's AI systems stop producing per-matter point-in-time opinions and start enforcing portfolio-level standards. Compliance officers and risk partners can query:
These questions answerable only when clauses are structured entities with canonical types, jurisdiction metadata, and precedent links transform AI from a per‑lawyer productivity tool into a firm‑wide interpretive governance layer. At that point, the system is not just “using AI to read text”; it is operationalising a single, standardised interpretation of key clauses across the entire organisation.
In a clause‑centric architecture, the quality of every downstream decision is bounded by the quality of the raw inputs ; garbage in, garbage out (GIGO) is not a slogan; it is the primary design constraint. If the pipeline ingests low‑fidelity scans, misclassified documents, or duplicate versions without alignment, even the best extraction models will produce structurally wrong clause data. A high‑quality ingestion layer is therefore not an optimisation; it is the foundation of the entire system.
In professional services environments, contracts and legal documents live across CLM platforms, DMS systems, shared drives, email, and line‑of‑business tools. A robust clause‑centric pipeline starts by raising the fidelity of the documents themselves before any AI model is applied:
Only once these preprocessing steps are complete does the pipeline proceed to structural parsing and clause extraction. The goal is simple: make sure the extraction models are always working on high‑fidelity, correctly classified, de‑duplicated inputs, so that errors in the clause store come from model limitations not from preventable input noise.
Once documents have been through layout‑aware OCR, de‑duplication, and version alignment, the system can safely treat the page as a structural object, not just a string of characters. The next step is to parse each document into its legal text units:
At this stage, the goal is not “chunking for embeddings” but reconstructing the legal hierarchy that existed in the authoring system. Legal text segmentation research emphasises that if the parser loses the distinction between a heading and a sub‑clause, or between a bullet and a new section, the downstream clause model will create obligations, exclusions, or carve‑outs that do not exist. To avoid this, the segmentation layer must be layout‑aware
Each resulting clause is assigned a stable identifier and section path (e.g., 3.2.1/Indemnity/Third‑Party Claims) that encodes its position in the hierarchy. This ensures that all downstream models; extraction, risk scoring, graph‑RAG operate on high‑fidelity clause units that preserve the original legal structure, not on artificial token windows.
Once clauses are identified, specialized NLP is applied at the clause level:
Legal knowledge extraction work shows that combining open information extraction tools with domain ontologies (event, time, role, obligation, jurisdiction) significantly improves the quality of structured legal data. LLMs can be used as controlled information extractors, with carefully designed prompts and schemas to prevent hallucination and ensure fields map to known taxonomies.
The output of this stage is not just text annotations; it is a first pass at the clause’s structured metadata. These fields are explicitly designed to be consumed by deterministic policy engines and SQL‑based compliance checks in later stages, with confidence scores marking which values are safe for automation and which must be human‑validated before they are allowed to gate decisions.
Raw extracted attributes are noisy. To support reliable decisions, the system must normalize and canonicalize:
Contract intelligence platforms typically use ML models and rule engines to categorize clauses as "standard", "acceptable deviation", or "non‑standard" compared to a firm’s templates and prior deals. These categories are stored as metadata fields that drive workflow and risk reporting, and this is the point where the firm’s risk posture becomes machine‑readable. Once every clause is mapped to a canonical type and playbook position, the system can enforce a standard interpretation across all matters instead of rediscovering it one contract at a time.
After extraction and normalization, clause entities and relationships are persisted into:
Graph‑based approaches allow modeling:
These structures enable both traditional query languages (SQL, Cypher, SPARQL) and graph‑RAG techniques where retrieval is constrained to legally coherent neighborhoods in the graph.
Persisting clauses and their relationships in this way is what turns the contract portfolio into a database rather than a library: every new agreement immediately enriches the clause graph, expanding the firm’s searchable universe of obligations, risk positions, and precedents for future negotiations.
In legal and compliance settings, every extracted datum must be explainable:
Taken together, these mechanisms turn the clause store into an auditable system of record for AI‑assisted legal decisions: every field has a source, every change has a reviewer, and every automated decision can be traced back to specific clause versions and metadata values.
.jpg)
Once clauses are modelled as structured entities with metadata, the system can adopt a hybrid architecture where deterministic logic and generative logic each do what they are best at and nothing more.
This separation of labour is what makes the system reliable and auditable for high‑stakes decisions. The decision whether a contract can be signed under current policy, whether a clause violates a risk threshold, whether a regulatory requirement is met is made by deterministic logic over structured clause data. The LLM explains, drafts, and contextualises that decision, but it does not substitute its own probabilistic judgment for the firm’s rules. Purely generative AI can never offer this level of control, because its behaviour is driven by prompts and weights, not by an explicit, inspectable policy layer.
In this design, RAG operates over structured clauses instead of raw text chunks, retrieving the legally complete neighbourhood of a provision (definition, carve‑outs, amendments, linked regulations) and handing that context to the LLM after deterministic filters have run. The generative layer becomes a user interface over a governed decision engine, rather than the decision engine itself.
-- Example: find all contracts where limitation of liability is "unlimited"
-- in EMEA, so they must be escalated under firm policy.
SELECT
c.id AS contract_id,
c.client_id,
c.counterparty_id,
c.jurisdiction,
cl.id AS clause_id,
cl.clause_number,
cl.canonical_type,
cm.value AS liability_cap_normalized
FROM contracts c
JOIN clauses cl
ON cl.contract_id = c.id
JOIN clause_metadata cm
ON cm.clause_id = cl.id
WHERE
c.jurisdiction IN ('UK', 'DE', 'FR', 'NL', 'IT') -- EMEA subset
AND cl.canonical_type = 'LIABILITY_LIMITATION'
AND cm.key = 'liability_cap.normalized'
AND cm.value = 'UNLIMITED'; This query powers a deterministic policy check: any row returned must be escalated, and the AI copilot can then generate explanations and negotiation positions grounded in the specific clause_id records, rather than guessing from free‑text.
Graph‑RAG for legal norms demonstrates that structure‑aware retrieval grounded in a formal model of legal entities and temporal versions produces more reliable answers than naive vector search. Applied to contracts, a structure‑aware RAG layer can:
LegalBench‑RAG and follow‑on work provide benchmarks for evaluating such retrieval strategies on legal tasks, emphasizing minimal, highly relevant snippets that match the exact legal references needed for a question.
In a knowledge‑graph implementation, a structure‑aware RAG layer would first retrieve the legally coherent neighbourhood of a clause, for example using a Cypher query like this, and only then hand that context to the LLM.
// Retrieve a liability clause and its legally relevant neighbourhood:
// related amendments and linked regulations.
MATCH (cl:Clause {id: $clauseId})
OPTIONAL MATCH (cl)-[:AMENDED_BY]->(amend:ClauseVersion)
OPTIONAL MATCH (cl)-[:REFERS_TO]->(reg:Regulation)
RETURN
cl.clause_number AS clause_number,
cl.canonical_type AS canonical_type,
cl.text AS clause_text,
collect(DISTINCT amend.text) AS amendments,
collect(DISTINCT reg.citation) AS related_regulations; With clause entities and structured metadata, firms can expose decision APIs that upstream systems call:
Behind these APIs, the system:
This design aligns AI behaviour with explicit firm policies rather than leaving decisions to free‑form generation.
Contract intelligence rarely lives in isolation. It must integrate with CLM platforms, document management systems, and matter management tools already used by legal, advisory, and compliance teams. Common patterns include:
Bidirectional synchronization ensures that manual edits by lawyers (e.g., updated playbook positions) are captured in the clause‑centric data store.
Because clause‑centric models expose structured attributes, standard BI and analytics tools can answer questions such as:
These insights help partners, risk committees, and compliance officers calibrate negotiation playbooks and firm‑wide policy.
Although the examples above focus on contracts, the same clause‑centric and graph‑based principles apply to other professional services assets:
A shared legal knowledge graph underlying these artefacts enables multi‑disciplinary views of client risk and obligations.
Relational databases provide strong consistency and mature tooling for transactional CLM operations, while graph databases excel at modelling references, dependencies, and temporal evolution in legal texts. Vector databases, by contrast, are optimised for similarity search, not for representing version graphs or cross‑references. They are easy to spin up, but they cannot, by design, answer questions like “what was the legally effective version of this clause on 1 January 2022?” or “which clauses does this carve‑out override?
For clause‑centric contract intelligence, this makes a hybrid relational–graph store less of a nice‑to‑have and more of a requirement:
Building and operating this hybrid store is objectively harder than spinning up a basic vector database. It requires schema design, migration planning, and careful operationalisation of both SQL and graph queries.
But it is also the only architecture that can correctly model temporal validity, clause versioning, and complex cross‑references at scale which are exactly the properties that matter in legal, advisory, and compliance work. In other words, the complexity is not architectural gold‑plating; it is the cost of getting legally meaningful answers instead of approximate ones.
Clause extraction and classification are probabilistic. LegalBench‑RAG and similar benchmarks provide a rigorous way to evaluate retrieval and extraction quality on legal tasks, emphasizing precise identification of relevant text units. In production, firms should:
Regulators increasingly expect explainable, controllable AI, especially in finance, legal, and compliance contexts. Clause‑centric architectures facilitate:
These features are difficult to achieve with purely unstructured RAG pipelines.
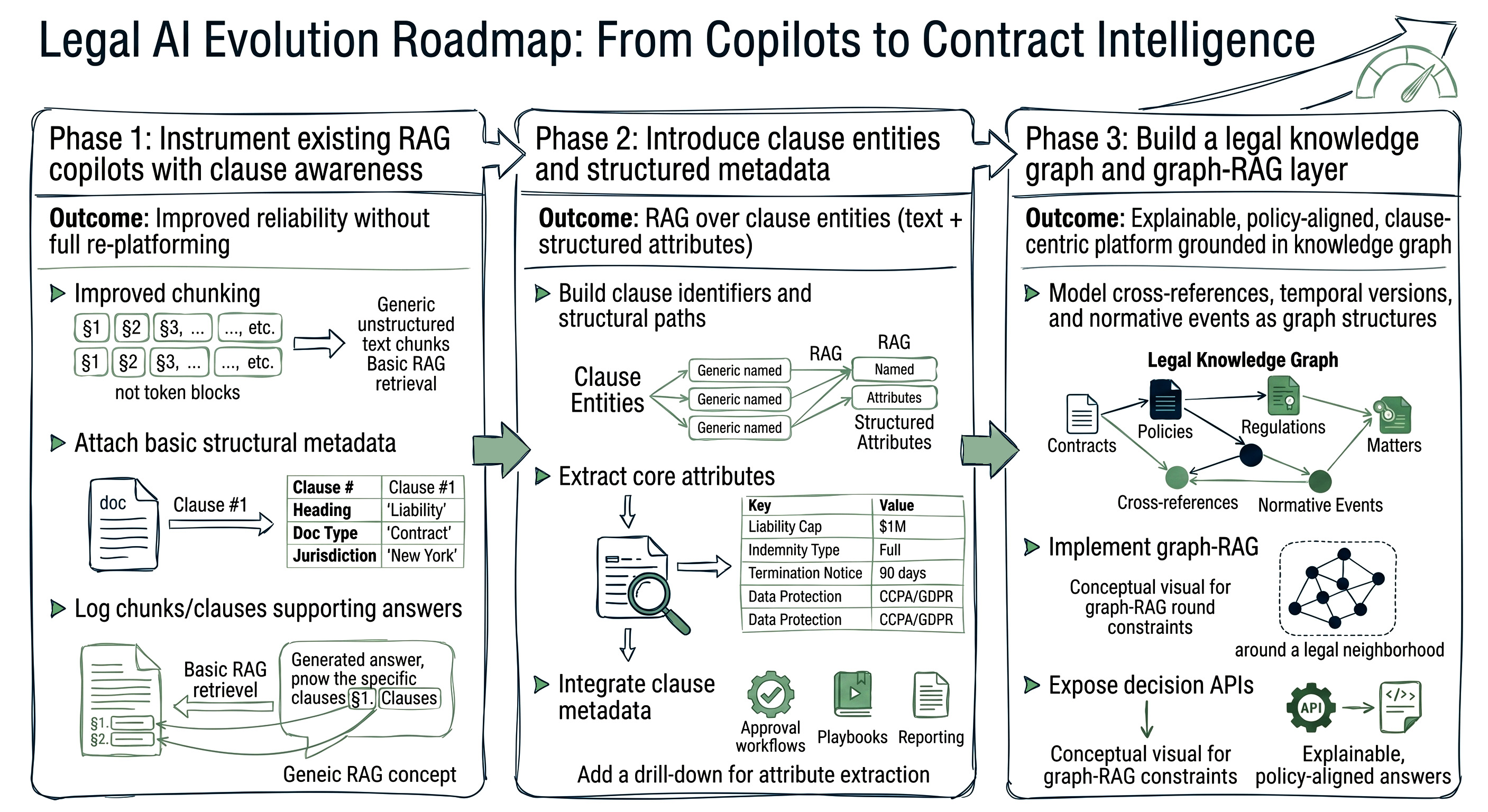
Firms with existing legal copilots can start by:
This phase improves reliability without full re‑platforming.
Next, introduce a clause entity store:
RAG retrieval can now operate over clause entities, with the LLM receiving both text and structured attributes.
Finally, construct a legal knowledge graph that unifies contracts, policies, regulations, and matters:
At this stage, the firm has moved from generic copilots to a contract intelligence platform where AI decisions are explainable, policy‑aligned, and grounded in a clause‑centric data model.
For legal, advisory, and compliance organisations, the real unlock from AI is not better drafting speed; it is defensible, auditable decisions grounded in the actual obligations and rights encoded in contracts. In regulated environments, every AI‑assisted answer must be traceable back to specific source text the exact clause version, in the exact contract, that supported the conclusion. Anything less is a liability disguised as automation.
Traditional, chunk‑based RAG cannot meet that standard. It operates on probabilistic similarity over text fragments, with no durable notion of clause identity, version history, or structural context. When it is wrong, there is no reliable way to see which obligation was missed, which carve‑out was ignored, or which version was misapplied.
Treating clauses as first‑class data entities with stable IDs, rich metadata, version graphs, and provenance links back to the original documents changes that. Every decision the system makes can be decomposed into:
That chain is reviewable, reproducible, and discoverable. It provides the evidence required for courtroom discovery, internal investigations, and regulatory audits, and it makes it possible to answer not just “what did the system decide?” but “why did it decide that, and which text did it rely on?”
In that sense, a clause‑centric architecture does more than turn AI into a productivity tool. It turns AI into a governance layer: a controlled, observable system that enforces the firm’s policies over its contract portfolio, with every answer anchored in clause‑level evidence that can stand up to scrutiny.