
Part 1 designs the end‑to‑end architecture for clause intelligence pipelines, from ingestion and clause extraction to a clause‑centric data model and storage layer that downstream risk engines can reliably query.
Professional services teams already see that “AI for contracts” is moving beyond summarization into structured clause extraction, tagging, and risk scoring. Several platforms now ingest PDFs/DOCX, identify clause types, and assign risk levels or flags that attorneys can review clause‑by‑clause. At the research frontier, systems like ContractSense and related work propose hybrid architectures combining accurate clause extraction, risk prediction, and explainable retrieval as the backbone for legal intelligence.
This part focuses on the architectural foundation: how to turn unstructured contracts into stable, clause‑centric data structures that risk engines can compute on consistently. Part 2 will go deeper into normalization steps and binary risk signals.
A clause intelligence pipeline is an end‑to‑end data and AI stack that:
Modern workflows like Langflow’s contract risk scanner and multi‑agent n8n flows already implement simplified versions of this pattern for clause extraction and risk scoring. What you want as an architect is a repeatable, auditable pipeline that isolates each stage into clear components and schemas.
At system level, a clause intelligence pipeline for legal/risk/compliance typically looks like this:
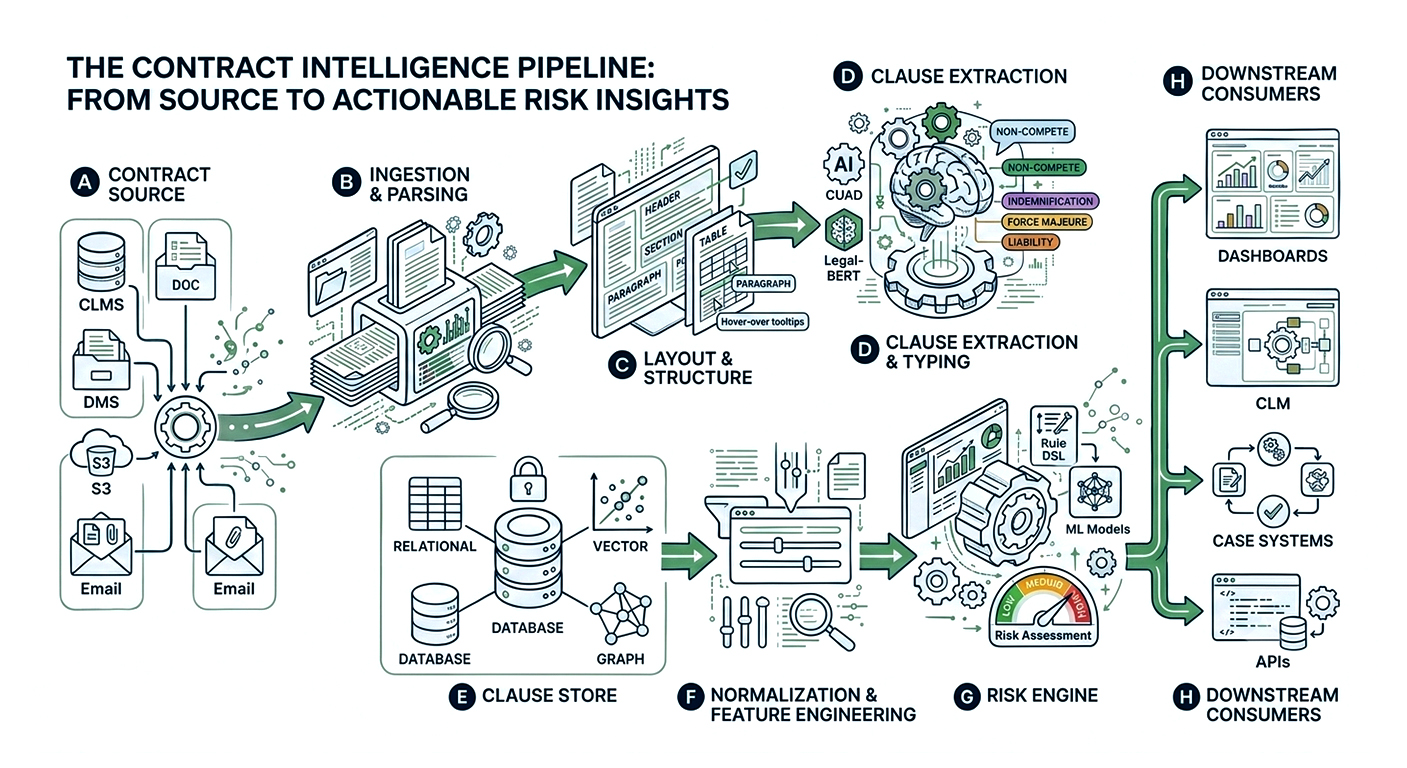
This mirrors production systems that separate a document processing pipeline, a clause classifier, and a risk scoring engine while feeding risk‑annotated outputs back into CLM or review workflows.
Each box in this diagram should correspond to deployable services or modules with their own contracts, tests, and observability.
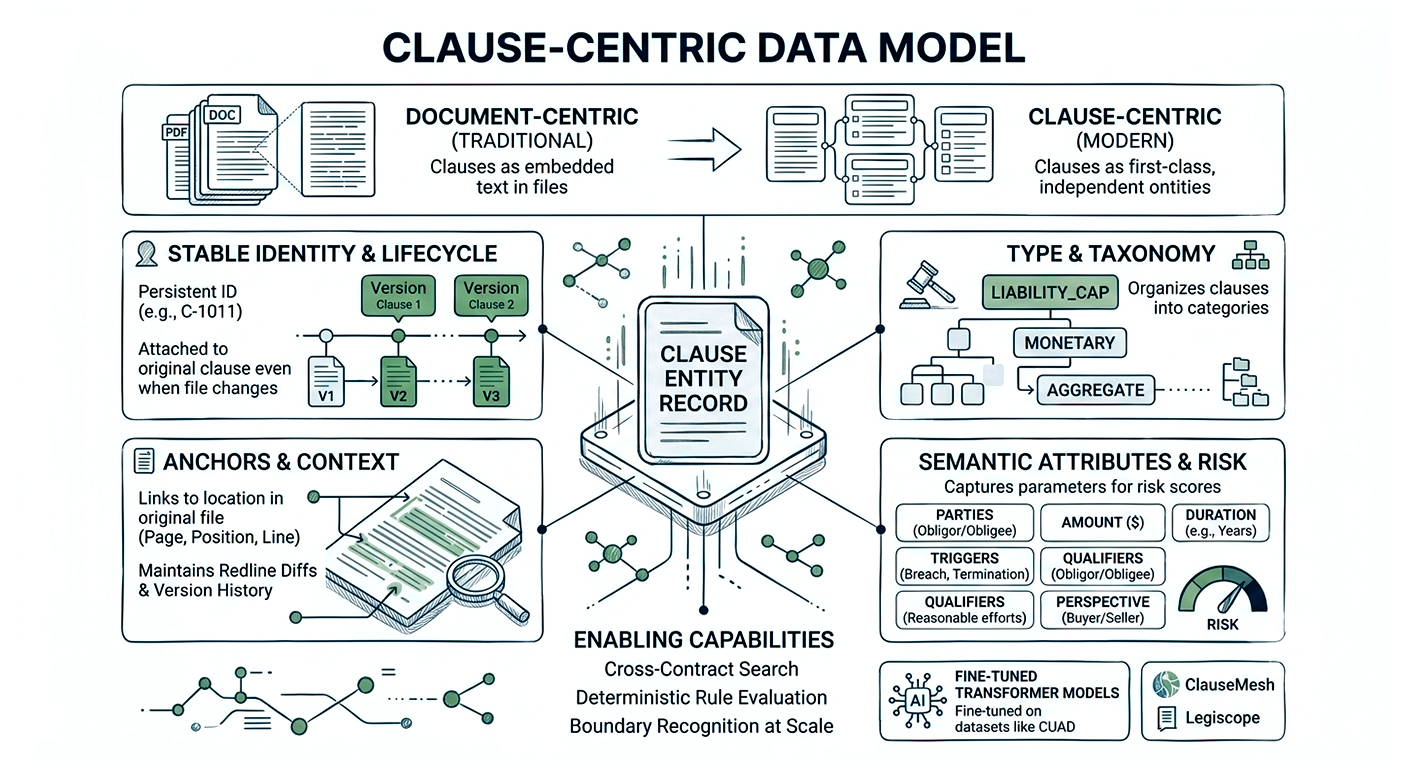
The core design decision is to treat clauses as first‑class entities, not just text spans inside a PDF. Platforms like ClauseMesh and Legiscope maintain clause‑level records tagged with clause types and risk scores, enabling cross‑contract search and deterministic rule evaluation. Research systems fine‑tune transformer models (often on datasets like CUAD) to recognize clause categories and boundaries at scale.
You need a data model that captures:
A minimal JSON representation might look like this:
{
"clause_id": "cl_9f4c8f3e",
"parent_clause_id": "cl_1a2b3c4d",
"document_id": "doc_msa_1234_v3",
"source_location": {
"page": 12,
"section_path": ["8", "8.3"],
"offset_start": 10342,
"offset_end": 10789
},
"raw_text": "Supplier's aggregate liability arising out of or in connection with this Agreement shall not exceed twelve (12) months of Fees paid under this Agreement...",
"canonical_type": "LIABILITY_CAP > AGGREGATE",
"parties": {
"our_party": "Customer",
"counterparty": "Supplier"
},
"jurisdiction": "US-NY",
"governing_law": "New York",
"attributes": {
"cap_basis": "aggregate",
"cap_multiple": 1.0,
"cap_reference_period_months": 12,
"includes_indirect_damages": false,
"excludes_confidentiality_breach": true
},
"vector_embedding_id": "emb_abc123",
"extracted_at": "2026-06-25T10:15:00Z",
"version": 3
}
"amendment_history": [
{
"amendment_id": "amd_001",
"parent_clause_id": "cl_1a2b3c4d",
"document_id": "doc_msa_1234_v2",
"change_type": "text_redline",
"changed_at": "2026-05-10T09:30:00Z",
"changed_by": "lawyer_789",
"previous_text": "Supplier's aggregate liability ... shall not exceed six (6) months of Fees ...",
"new_text": "Supplier's aggregate liability ... shall not exceed twelve (12) months of Fees ..."
}
] }
This schema is aligned with how clause libraries and risk frameworks track clause types, numeric thresholds, and jurisdiction for downstream evaluation and search.
You can materialize this into a relational schema (PostgreSQL), a graph schema (Neo4j, TypeDB), and a vector index (Qdrant, Pinecone) in parallel.
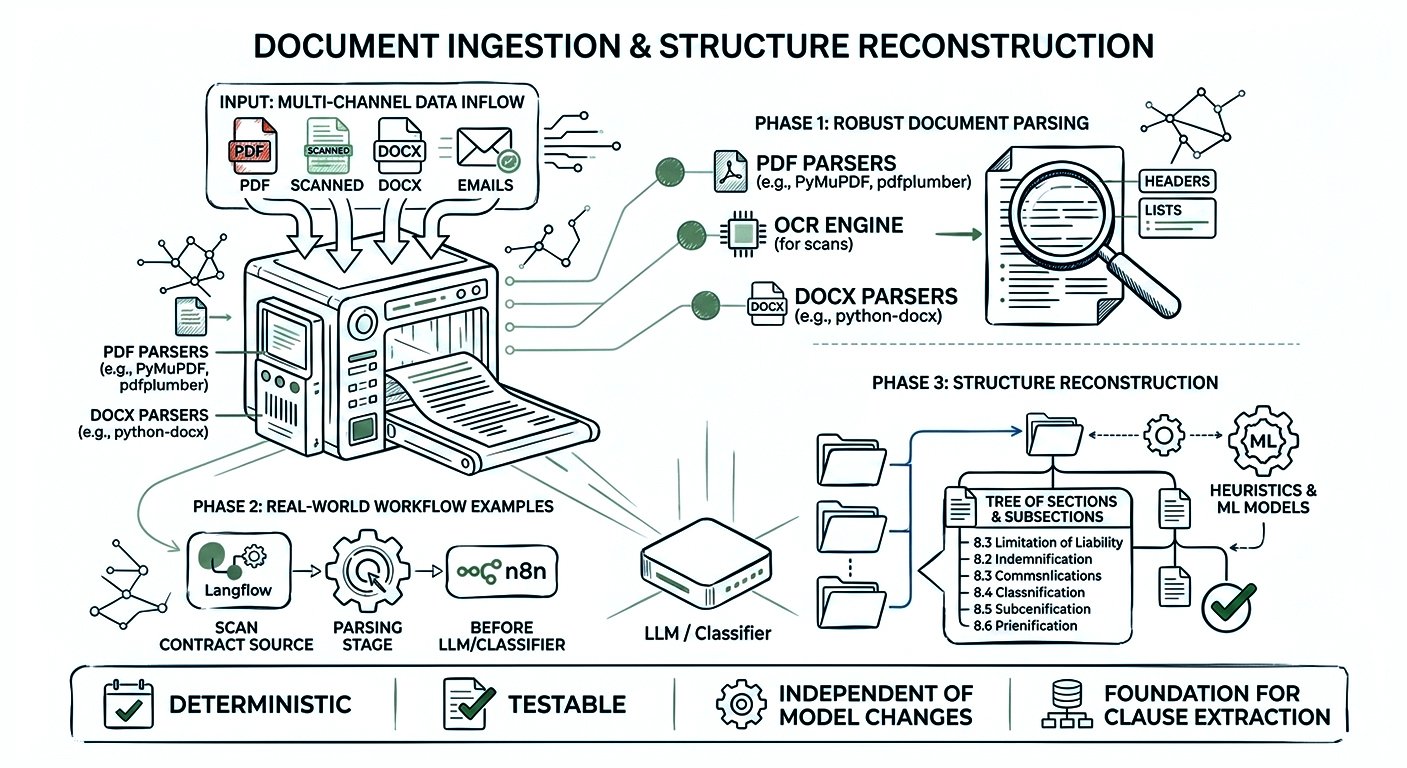
Before you can extract clauses, you need robust document parsing. Real implementations use:
A typical ingestion worker might look like this (Python‑style pseudocode):
from uuid import uuid4
from my_parsers import parse_pdf, parse_docx
from my_layout import build_outline_tree, detect_clauses
# This worker is invoked asynchronously from a message queue (e.g., RabbitMQ, Kafka, AWS SQS)
# as part of an event-driven ingestion pipeline. Each message represents a single document
# ingestion event, allowing heavy PDF/OCR parsing to be distributed across multiple workers
# instead of blocking a synchronous API call.
def ingest_document(source_uri: str, mime_type: str) -> str:
if mime_type == "application/pdf":
pages = parse_pdf(source_uri)
elif mime_type in ("application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"application/msword"):
pages = parse_docx(source_uri)
else:
raise ValueError(f"Unsupported type: {mime_type}")
# For large PDFs or OCR-heavy scans, pages can be chunked (e.g., 50-page blocks)
# and processed in separate worker invocations to avoid timeouts and to keep
# ingestion idempotent. Each chunk publishes clause spans back onto the queue,
# and downstream consumers reconcile chunks into a single document-level clause set.
outline = build_outline_tree(pages)
clause_spans = detect_clauses(outline)
document_id = f"doc_{uuid4().hex}"
# Persist raw spans at document level; detailed typing happens later in a separate
# asynchronous classification stage, keeping this worker focused solely on structured
# data extraction from the source document.
for span in clause_spans:
save_raw_clause_span(
document_id=document_id,
page=span.page,
section_path=span.section_path,
offset_start=span.offset_start,
offset_end=span.offset_end,
text=span.text,
)
return document_id
Langflow and n8n workflows that scan contracts for risk typically include similar parsing nodes as the first stages before any LLM or classifier is invoked. You want ingestion to be deterministic, testable, and independent of model changes.
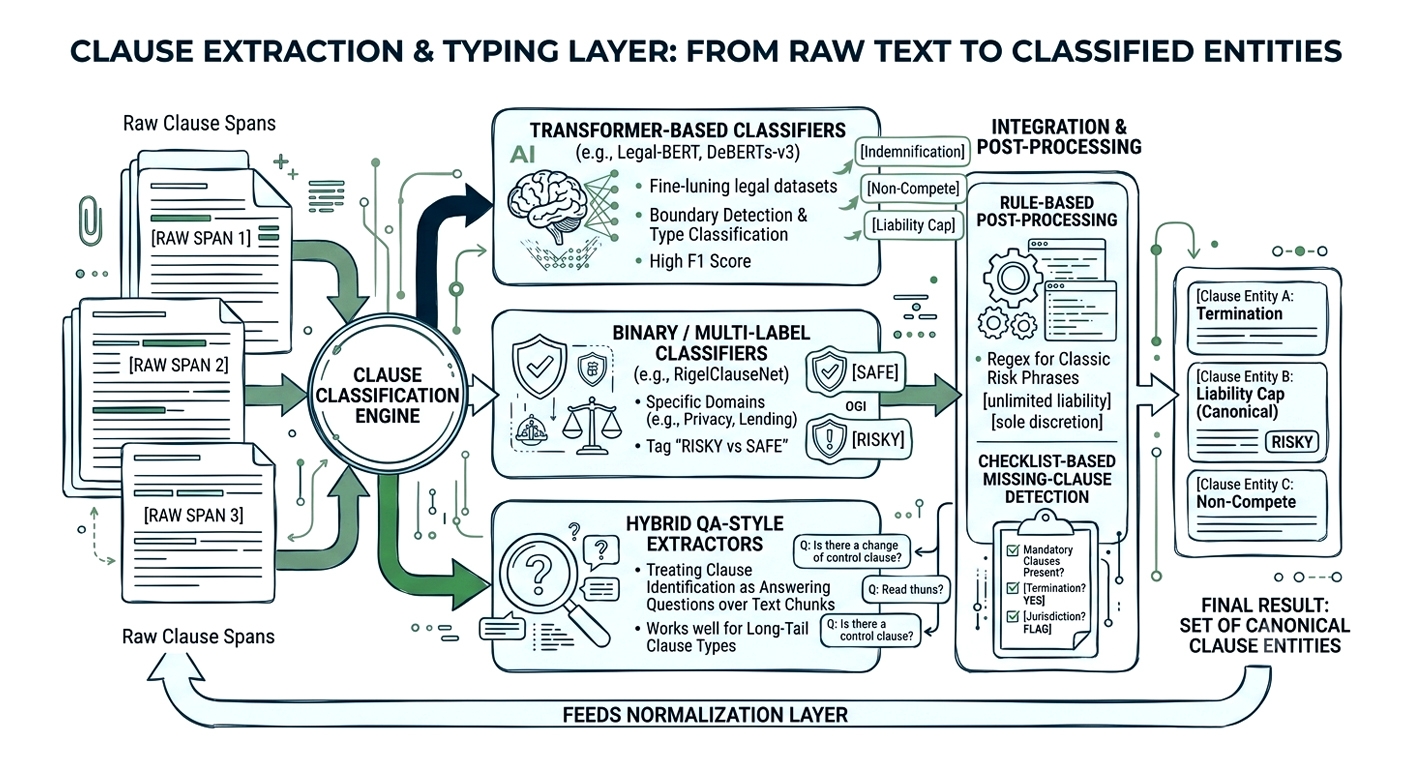
Once you have raw clause spans, you classify each into one or more clause types:
A simplified classification function (using a Hugging Face model) could look like:
from transformers import AutoTokenizer,
AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("nlpaueb/legal-bert-base-uncased") # domain-adapted Legal-BERT backbone for clause classification[web:58]
model = AutoModelForSequenceClassification.from_pretrained("my-org/clause-type-classifier")
id2label = model.config.id2label
# In production, thresholds are calibrated per clause type rather than using a single global 0.5 cut-off.
# Rare, long-tail clause categories (e.g., niche indemnities or unusual data-transfer provisions) often
# require lower or asymmetric thresholds, informed by validation curves or cost-sensitive metrics, to avoid # systematically under-detecting low-frequency but high-risk classes.[web:46][web:49][web:52]
CLAUSE_TYPE_THRESHOLDS = {
# e.g., 'LIABILITY_CAP > AGGREGATE': 0.6,
# 'DATA_PROTECTION > DPA': 0.55,
# 'FORCE_MAJEURE': 0.45,
}
DEFAULT_THRESHOLD = 0.5
def classify_clause(raw_text: str) -> list[str]:
inputs = tokenizer(raw_text, return_tensors="pt", truncation=True, padding=True, max_length=512)
with torch.no_grad():
logits = model(**inputs).logits
probs = torch.sigmoid(logits)[0]
labels = [
id2label[i]
for i, p in enumerate(probs)
if p.item() > 0.5
]
return labels
Production systems often combine this with rule‑based post‑processing (e.g., regex for classic risk phrases like “unlimited liability”, “sole discretion”) and checklist‑based missing‑clause detection. The result is a set of clause entities with one or more canonical types that feed the normalization layer.
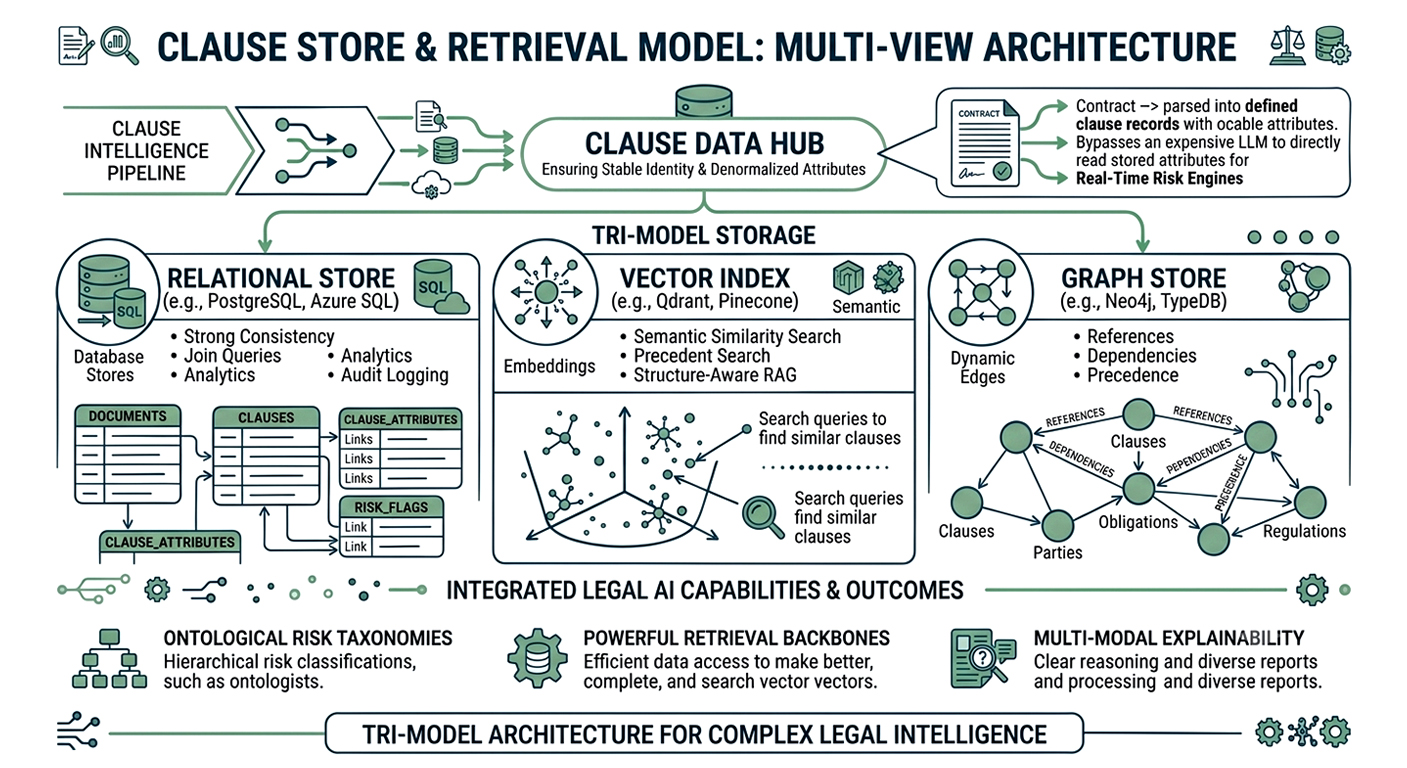
To support both deterministic engines and LLM workflows, most modern architectures maintain multiple views over clause data:
This tri‑model storage is consistent with research recommended architectures that combine ontological risk taxonomies, retrieval backbones, and multi‑modal explainability for legal AI.
For clause intelligence pipelines, the key design choice is to ensure each clause has a stable identity and denormalized attributes that risk engines can read without re‑invoking expensive models in real time.
CREATE TABLE clause (
clause_id VARCHAR PRIMARY KEY,
document_id VARCHAR NOT NULL,
canonical_type VARCHAR NOT NULL,
raw_text TEXT NOT NULL,
jurisdiction VARCHAR,
governing_law VARCHAR,
parties_our_side VARCHAR,
parties_counter VARCHAR,
extracted_at TIMESTAMP NOT NULL,
version INT NOT NULL
);
-- For stable, frequently queried attributes (like cap_multiple or excludes_confidentiality_breach),
-- a flat clause_attributes table works well. However, real-world clause taxonomies introduce highly
-- dynamic semantic attributes that vary by clause type, product line, jurisdiction, and policy version.
-- To avoid an explosion of nullable columns and infinite joins, a hybrid pattern using JSONB is preferred: --
-- * Store flexible, clause-type-specific attributes in a JSONB column.
-- * Add a GIN index on that JSONB column to support containment and key/kv lookups across attributes.
--
-- Example:
-- attributes -> '{ "cap_basis": "aggregate", "cap_multiple": 1.0,
-- "includes_indirect_damages": false,
-- "excludes_confidentiality_breach": true }'
--
CREATE TABLE clause_attributes (
clause_id VARCHAR NOT NULL REFERENCES clause(clause_id), attributes JSONB );
-- GIN index over JSONB to efficiently query dynamic semantic attributes CREATE INDEX idx_clause_attributes_gin
ON clause_attributes
USING GIN (attributes jsonb_path_ops);
In practice, highly dynamic semantic attributes across different clause taxonomies are best handled with a hybrid relational–document model: a JSONB attributes column indexed with GIN for containment and key/value queries, rather than proliferating dozens of nullable columns and joins.
In Part 2, we will formalize how to go from raw_text and clause_attributes to binary risk features and consistent contract‑level risk scores.
By the end of Part 1, the pipeline is no longer a generic “legal RAG” concept but a concrete contract‑to‑clause architecture: documents are ingested through a layout‑aware parser, clause spans are identified and typed by legal‑specific models, and each clause is persisted as a first‑class entity with stable IDs, metadata, and links back to the original text.
This mirrors the internal design of modern contract risk and clause intelligence platforms, which separate document processing, clause classification, and storage into independently deployable services backed by relational, vector, and sometimes graph stores.
Part 2 builds directly on this foundation by treating each stored clause as a unit of computation: we will define the normalization steps that turn raw legal prose into canonical attributes, show how organization‑specific policies compile into executable rules, and demonstrate how those rules produce binary risk features and contract‑level scores that downstream engines, dashboards, and LLM assistants can consume without re‑parsing the document.
In other words, Part 2 turns the clause store you have now into a deterministic risk signal factory that can be versioned, tested, and audited like any other critical enterprise service.