
Part 2 extends the system metagraph with semantic data contracts and behavioral ledger patterns, activating deterministic AI guardrails that enforce risk-aware refactoring, targeted test generation, and controlled deployment automation across undocumented polyglot legacy estates.
In Part 1, we built a living, multi-layer system graph from undocumented codebases: topology, static dependencies, runtime behavior weights, and risk metadata. That graph gives us “where” and “how things connect.”
To make AI useful and safe we now need “what flows where” and “how it behaves over time”: data contracts and behavioral patterns. This is the jump from structural understanding to semantic understanding, which is where naive AI refactoring efforts usually fail.
In this part we will:
Legacy systems rarely have explicit, versioned API or data contracts; they have ad-hoc SQL queries, batch file layouts, and tribal knowledge about “what this job expects.” Yet data loss and corruption are among the highest risks in modernization programs.
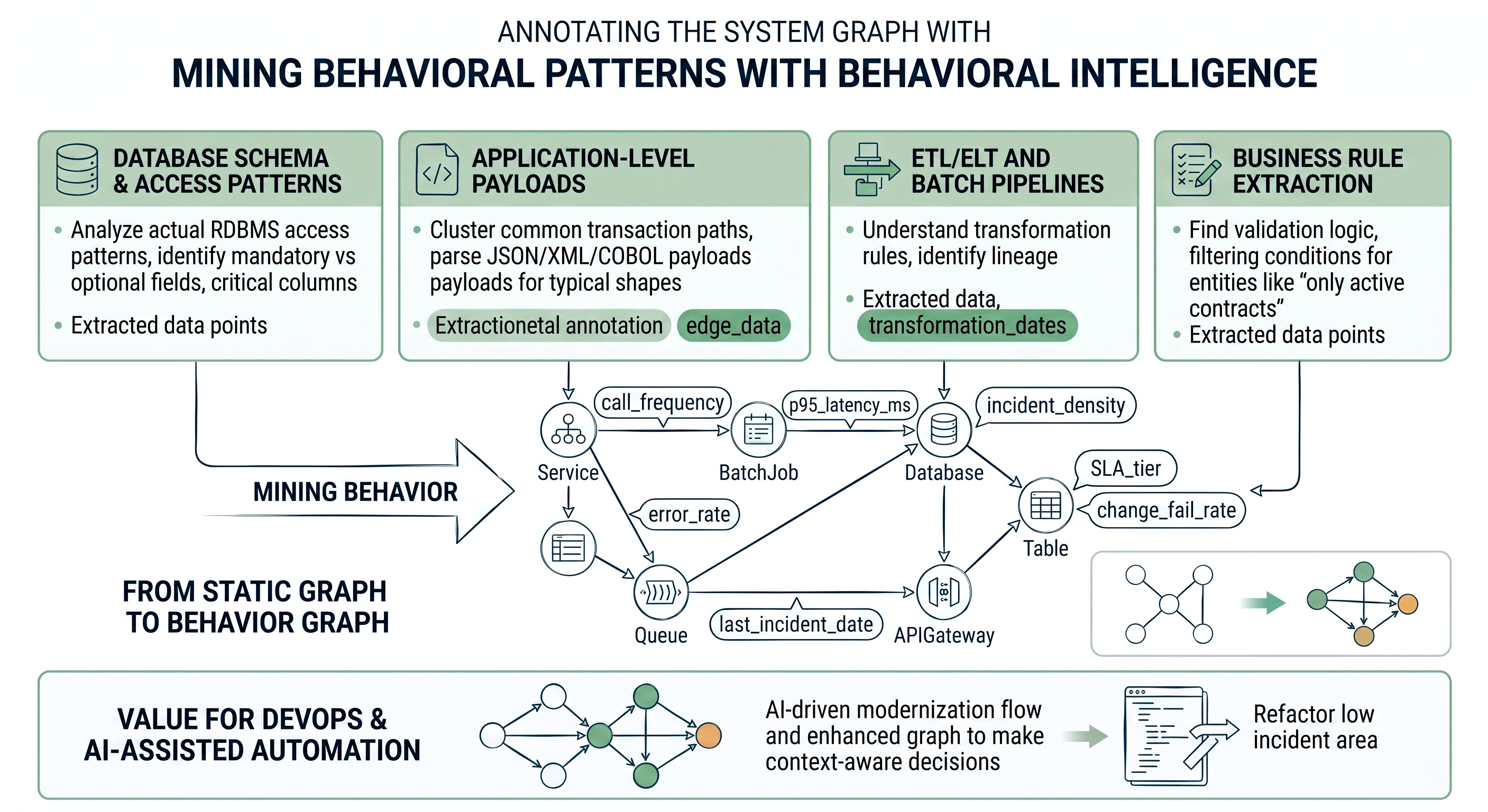
To reduce that risk, we need to infer data contracts from multiple lenses:
.jpg)
1. Database schema and access patterns
At this scale, simply listing tables and consumers is not enough; you need Semantic Schema Extraction and Lineage Reconstruction that reflects how data is actually used and constrained in production, not just how it is declared in DDL.
Instead of treating the database as a static schema plus a folder of .sql files, the pipeline:
1. Reads active database catalogs (information schema, system catalogs, constraint tables) to extract primary keys, foreign keys, check constraints, unique indexes, and default values as first‑class invariants.
2. Mines query plans, statement logs, and CDC streams to understand how data flows through the estate: which tables are joined, which columns are filtered on, which fields are effectively mandatory, and which values appear in practice.
3. Reconstructs semantic lineage from source tables through views, stored procedures, ETL jobs, and reporting layers, tagging each transformation step with its derivation logic and loss/aggregation characteristics.
From this, the system can synthesize version‑controlled, machine‑readable contracts for key entities (e.g., Invoice, Policy, Customer) that look less like a raw table definition and more like an API surface:
{
"contract": "Invoice.v3",
"backing_tables": ["billing.invoice", "billing.invoice_item"],
"fields": {
"invoiceId": {
"type": "uuid",
"nullable": false,
"key": true,
"source": "billing.invoice.invoice_id",
"invariants": ["unique", "non_empty"]
},
"amount": {
"type": "decimal(18,2)",
"nullable": false,
"source": "SUM(billing.invoice_item.line_amount)",
"invariants": [">= 0"]
},
"currency": {
"type": "string",
"nullable": false,
"source": "billing.invoice.currency",
"domain": "ISO_4217"
},
"status": {
"type": "string",
"nullable": false,
"source": "billing.invoice.status",
"allowed_values": ["PENDING", "PAID", "CANCELLED"]
}
},
"producers": [
"batch/legacy_invoice_run",
"api/billing-service"
],
"consumers": [
"reporting/invoice_report",
"etl/dwh_invoice_facts"
]
}
These contracts can then be materialized as OpenAPI schemas, Protocol Buffers, Avro schemas, or JSON Schema, and stored in a versioned registry. The key is that they are:
Before any modernization or AI‑driven refactoring begins, these machine‑readable contracts are treated as data integrity guardrails: code changes must not violate the contracts, and any proposed schema or contract evolution is evaluated against known producers, consumers, and invariants in the graph. This flips data contracts from being optional documentation to being part of the hard safety boundary for automated change.
2. Application-level payloads
In many of the estates that matter most—core banking, policy administration, billing, settlements—the primary integration surface is not JSON over HTTP, but binary and positional payloads defined by COBOL copybooks and fixed‑length files.
A typical copybook might define a record like:
01 INVOICE-RECORD.
05 INVOICE-ID PIC X(12).
05 ACCOUNT-ID PIC X(10).
05 INVOICE-DATE PIC 9(8).
05 CURRENCY-CODE PIC X(3).
05 GROSS-AMOUNT PIC 9(11)V99.
05 TAX-AMOUNT PIC 9(9)V99.
05 NET-AMOUNT PIC 9(11)V99.
05 STATUS-CODE PIC X(1). On disk or over MQ, this is just a dense byte stream; the semantics live entirely in the copybook and in the downstream jobs that assume a specific positional layout. To make this usable for AI‑assisted refactoring and contract enforcement, we build custom ingestion engines that:
Conceptually, the ingestion pipeline produces contracts like:
{
"contract": "InvoiceRecord.v1",
"source": {
"type": "copybook",
"name": "INVOICE-RECORD",
"file": "INVOICE.CPY"
},
"encoding": {
"format": "fixed-length",
"length": 56,
"charset": "EBCDIC"
},
"fields": [
{
"name": "invoiceId",
"offset": 0,
"length": 12,
"type": "string"
},
{
"name": "accountId",
"offset": 12,
"length": 10,
"type": "string"
},
{
"name": "invoiceDate",
"offset": 22,
"length": 8,
"type": "date",
"format": "yyyyMMdd"
},
{
"name": "currency",
"offset": 30,
"length": 3,
"type": "string",
"domain": "ISO_4217"
},
{
"name": "netAmount",
"offset": 43,
"length": 13,
"type": "decimal",
"scale": 2,
"impliedDecimal": true
},
{
"name": "status",
"offset": 56,
"length": 1,
"type": "string",
"allowedValues": ["O", "P", "C"] // Open, Paid, Cancelled
}
]
} Those schemas are then promoted into the metagraph as DataContract nodes, linked to the COBOL programs and batch jobs that produce or consume them, and optionally projected into OpenAPI or Avro for downstream services that want to interact with the same records over more modern transports.
The key outcome is that a previously opaque, positional payload becomes a typed, semantic contract with machine‑readable invariants and provenance. That contract can be enforced in test harnesses, used as a guardrail for AI‑generated changes, and versioned safely as you gradually migrate or re‑platform the underlying COBOL workloads.
3. ETL/ELT and batch pipelines
Once compiled, these OpenLineage events are ingested into the central metagraph as first-class edges:
This gives the AI agent full, cross-platform visibility into how data is shaped as it moves from source systems through legacy ETL tools, Spark jobs, and warehouse loads. Instead of guessing from scattered mappings, the agent can see exactly which fields are derived where, which pipelines depend on a contract, and what the blast radius of a change to a column or rule would be.
4. Business rule extraction
From this, you construct data contract nodes in your graph:
A simple static analysis can run and pass that scans route handlers, infers field names and types, and materializes an API contract:
{
"contract": "InvoiceAPI.v1",
"path": "/api/invoices",
"method": "POST",
"request_fields": {
"customerId": "string",
"amount": "number",
"currency": "string?"
},
"response_fields": {
"invoiceId": "string",
"customerId": "string",
"amount": "number",
"currency": "string",
"status": "string"
}
}
AI models then operate on these contracts instead of inferring structure from arbitrary samples every time.
For example, an AI-assisted refactoring task might be prompted with:
“Here is the Invoice contract with fields, constraints, and known producers/consumers. Refactor this batch job to break out tax calculation into a separate module while preserving the contract and all constraints.”
This is fundamentally safer than “refactor this 3,000-line COBOL program and hope nothing breaks.”
Behavioral patterns encode how the system actually behaves in production, not how it was intended to behave. Technical debt becomes dangerous when teams can no longer predict that behavior or its impact on change.
To mine behavior:
1. APM traces and logs
In practice, counting edges in a CSV is the least interesting part. What we really want is Operational Volatility Profiling: continuously streaming production telemetry into the metagraph to quantify how fragile each component and interaction actually is.
Instead of offline CSVs, the pipeline subscribes to:
These streams are aggregated into a Fragility Index per node and edge in the graph, combining:
Conceptually, for each component you maintain a rolling Fragility Index:
def compute_fragility(structural_score, incident_rate, change_fail_rate, drift_score):
# All inputs are normalized 0..1
return (
0.4 * structural_score +
0.3 * incident_rate +
0.2 * change_fail_rate +
0.1 * drift_score
) Components and contracts whose Fragility Index crosses a threshold are automatically marked in the metagraph as locked zones:
This turns behavioral telemetry and incident history into a live control surface: AI agents are not just “aware” of production behavior, they are explicitly constrained by it. Fragile, high‑volatility areas become fenced off until humans decide how, when, and whether to touch them.
2. Job history and scheduler metadata
Example: parse basic cron files and correlate with runtime metrics:
import pathlib
import re
CRON_RE = re.compile(r"^(\S+\s+\S+\s+\S+\s+\S+\s+\S+)\s+(.+)$")
jobs = {}
for cron_file in pathlib.Path("/etc/cron.d").glob("*"):
for line in cron_file.read_text().splitlines():
line = line.strip()
if not line or line.startswith("#"):
continue
m = CRON_RE.match(line)
if not m:
continue
schedule, cmd = m.groups()
job_id = cmd.split()[0]
jobs[job_id] = {"schedule": schedule, "cmd": cmd}
print(jobs) You then join this with job-duration and failure data from logs to identify fragile chains and SLAs.
3. Incident and problem management data
4. Semantic drift detection
These behavioral annotations turn the static system graph into a behavior graph:
This is invaluable for both DevOps and AI-assisted automation. It allows you to align AI activity not just with structure, but with operational reality.
By this point, you have:
To make this consumable:
.jpg)
1. Choose a graph backbone
2. Define a consistent ontology
3. Index for AI and DevOps queries
4. Expose graph APIs and embeddings
With topology, dependencies, data contracts, and behavior in place, you consolidate into an AI-ready system knowledge graph.
A minimal schema in Python (using NetworkX as an in-memory example):
Pseudo-code: Enterprise Graph Backplane (Neo4j example)
The example below shows a cleaner pattern for working with an enterprise graph backplane rather than an in-memory graph. It groups related responsibilities into configuration, graph operations, and example usage.
from dataclasses import dataclass
from typing import Any, Dict, List
from neo4j import GraphDatabase
@dataclass
class GraphConfig:
uri: str
user: str
password: str
class GraphBackplane:
"""Thin client for an enterprise graph backplane.
Assumes a strict ontology with labels such as RuntimeComponent:Service
and DataAsset:DataContract, plus relationships such as PRODUCES,
CONSUMES, CALLS, and DEPENDS_ON.
"""
def __init__(self, config: GraphConfig):
self._driver = GraphDatabase.driver(
config.uri,
auth=(config.user, config.password),
)
def close(self):
self._driver.close()
def upsert_service(self, name: str, **attrs: Any):
"""Create or update a Service node with indexed properties."""
cypher = """
MERGE (s:SystemEntity:RuntimeComponent:Service {name: $name})
ON CREATE SET s.created_at = timestamp()
SET s += $attrs
"""
with self._driver.session() as session:
session.run(cypher, name=name, attrs=attrs)
def upsert_datacontract(self, name: str, **attrs: Any):
"""Create or update a DataContract node."""
cypher = """
MERGE (c:SystemEntity:DataAsset:DataContract {name: $name})
ON CREATE SET c.created_at = timestamp()
SET c += $attrs
"""
with self._driver.session() as session:
session.run(cypher, name=name, attrs=attrs)
def link_produces(self, service: str, contract: str, **rel_props: Any):
"""Link a Service to a DataContract with a PRODUCES relationship."""
cypher = """
MATCH (s:Service {name: $service})
MATCH (c:DataContract {name: $contract})
MERGE (s)-[r:PRODUCES]->(c)
SET r += $rel_props
"""
with self._driver.session() as session:
session.run(cypher, service=service, contract=contract, rel_props=rel_props)
def link_consumes(self, service: str, contract: str, **rel_props: Any):
"""Link a Service to a DataContract with a CONSUMES relationship."""
cypher = """
MATCH (s:Service {name: $service})
MATCH (c:DataContract {name: $contract})
MERGE (s)-[r:CONSUMES]->(c)
SET r += $rel_props
"""
with self._driver.session() as session:
session.run(cypher, service=service, contract=contract, rel_props=rel_props)
def semantic_search_services(self, query: str, top_k: int = 10) -> List[Dict[str, Any]]:
"""Example of a hybrid vector-plus-graph query.
1) Query a vector index for semantically similar nodes.
2) Filter results to Service nodes and return key metadata.
"""
cypher = """
CALL db.index.vector.queryNodes('service_embeddings', $top_k, $query_vector)
YIELD node, score
WHERE node:Service
RETURN
node.name AS name,
node.domain AS domain,
node.criticality AS criticality,
score
ORDER BY score DESC
"""
raise NotImplementedError(
"Embed the query text and pass it as $query_vector."
)
from neo4j import GraphDatabase
@dataclass class GraphConfig: uri: str user: str password: str
class GraphBackplane: """ Thin client over an enterprise graph backplane (Neo4j/Neptune-like), assuming a strict system ontology: - Node labels: :RuntimeComponent:Service, :DataAsset:DataContract, etc. - Relationship types: PRODUCES, CONSUMES, CALLS, DEPENDS_ON, ... """ def init(self, config: GraphConfig): self._driver = GraphDatabase.driver(config.uri, auth=(config.user, config.password))
def close(self):
self._driver.close()
def upsert_service(self, name: str, **attrs: Any):
"""
Create/update a Service node with ontology labels and indexed properties.
"""
cypher = """
MERGE (s:SystemEntity:RuntimeComponent:Service { name: $name })
ON CREATE SET s.created_at = timestamp()
SET s += $attrs
"""
with self._driver.session() as session:
session.run(cypher, name=name, attrs=attrs)
def upsert_datacontract(self, name: str, **attrs: Any):
"""
Create/update a DataContract node (a subtype of DataAsset).
"""
cypher = """
MERGE (c:SystemEntity:DataAsset:DataContract { name: $name })
ON CREATE SET c.created_at = timestamp()
SET c += $attrs
"""
with self._driver.session() as session:
session.run(cypher, name=name, attrs=attrs)
def link_produces(self, service: str, contract: str, **rel_props: Any):
"""
Link Service -> DataContract with PRODUCES, attaching lineage and runtime props.
"""
cypher = """
MATCH (s:Service { name: $service })
MATCH (c:DataContract { name: $contract })
MERGE (s)-[r:PRODUCES]->(c)
SET r += $rel_props
"""
with self._driver.session() as session:
session.run(cypher, service=service, contract=contract, rel_props=rel_props)
def link_consumes(self, service: str, contract: str, **rel_props: Any):
"""
Link Service -> DataContract with CONSUMES, used for blast-radius queries.
"""
cypher = """
MATCH (s:Service { name: $service })
MATCH (c:DataContract { name: $contract })
MERGE (s)-[r:CONSUMES]->(c)
SET r += $rel_props
"""
with self._driver.session() as session:
session.run(cypher, service=service, contract=contract, rel_props=rel_props)
def semantic_search_services(self, query: str, top_k: int = 10) -> List[Dict[str, Any]]:
"""
Example of a hybrid “vector + graph” query:
1) Use a vector index on node_embeddings to find semantically similar nodes.
2) Filter to Services and project relevant metadata.
(Actual vector index syntax depends on the graph platform.)
"""
cypher = """
// Pseudo-Cypher for vector search + ontology filter
CALL db.index.vector.queryNodes('service_embeddings', $top_k, $query_vector)
YIELD node, score
WHERE node:Service
RETURN node.name AS name,
node.domain AS domain,
node.criticality AS criticality,
score
ORDER BY score DESC
"""
# query_vector would be injected by embedding the 'query' text externally.
raise NotImplementedError("Embed `query` to a vector and pass as $query_vector")
Example usage
config = GraphConfig(
uri="neo4j://graph-backplane.internal:7687",
user="graph_user",
password="*****",
)
backplane = GraphBackplane(config)
backplane.upsert_service(
"billing",
domain="FINANCE",
criticality="HIGH",
regulatory_scope=["SOX", "PCI"],
)
backplane.upsert_datacontract(
"Invoice",
version="v3",
schema={
"fields": ["invoiceId", "amount", "currency", "status"],
"domain": "BILLING_INVOICE",
},
)
backplane.link_produces(
"billing",
"Invoice",
lineage_step_id="etl_billing_001",
runtime_freq=12000,
p95_latency_ms=35,
)
backplane.close()
backplane = GraphBackplane(config)
backplane.upsert_service( "billing", domain="FINANCE", criticality="HIGH", regulatory_scope=["SOX", "PCI"], )
backplane.upsert_datacontract( "Invoice", version="v3", schema={ "fields": ["invoiceId", "amount", "currency", "status"], "domain": "BILLING_INVOICE", }, )
backplane.link_produces( "billing", "Invoice", lineage_step_id="etl_billing_001", runtime_freq=12000, p95_latency_ms=35, )
backplane.close()
Note: For production, you would persist this to a graph database and expose it via APIs and embeddings for AI agents.
At this stage, your estate is no longer an opaque blob of code. It is a navigable knowledge graph that DevOps tools and AI agents can reason over.
With the knowledge graph in place, AI-assisted refactoring can move from “best-effort suggestions” to risk-aware, graph-grounded workflows. Modern AI tools already demonstrate strong capabilities in refactoring and modernization when supported by structural analysis and validation harnesses.
A robust pattern looks like this:
1. Scope selection via graph queries
2. Context assembly for the AI agent
Pseudo-code for a “safe scope” selection query:
def safe_refactor_candidates(g, max_incident_density=0.1, max_out_degree=5):
candidates = []
for node, data in g.nodes(data=True):
if data.get("type") != "Service":
continue
if data.get("criticality") == "HIGH":
continue
if data.get("incident_density", 0.0) > max_incident_density:
continue
out_degree = g.out_degree(node)
if out_degree > max_out_degree:
continue
candidates.append(node)
return candidates Note: This function is then used to drive programmatic AI refactoring campaigns on safer parts of the estate.
Enterprises that follow this pattern report higher automation in refactoring tasks while maintaining strict control over business-critical logic.
The graph is the safety net AI acts inside clearly defined fences.
Legacy systems often lack automated tests; this is a core reason modernization feels dangerous.
AI-ready system intelligence enables three powerful test strategies:
1. Characterization tests for behavior preservation
Example: a Jest snippet for a Node.js billing service characterization test:
const request = require("supertest");
const app = require("../app");
describe("Billing characterization", () => {
it("should preserve behavior for known invoice payload", async () => {
const res = await request(app)
.post("/api/invoices")
.send({
customerId: "CUST-123",
amount: 100.50,
currency: "USD"
});
expect(res.status).toBe(201);
expect(res.body.invoiceId).toMatch(/^INV-/);
expect(res.body.currency).toBe("USD");
expect(res.body.status).toBe("PENDING");
});
}); An AI agent can draft such tests given contract + sample traces, then humans refine them.
2. Contract tests across services and batches
Example: Python pytest for a contract asserting output schema:
from schema import Schema, And
invoice_schema = Schema({
"invoiceId": And(str, lambda s: s.startswith("INV-")),
"customerId": str,
"amount": And(float, lambda v: v > 0),
"currency": And(str, lambda s: len(s) == 3),
"status": str
})
def test_invoice_producer_contract(sample_invoice_event):
invoice_schema.validate(sample_invoice_event) Such tests provide a hard constraint for AI‑generated refactors: the model must keep these guarantees intact.
3. Impact-based test selection in CI/CD
Rather than aim for “100% test coverage,” this approach targets risk-weighted coverage, guided by the system intelligence graph.
Big-bang migrations are notoriously risky; phased, graph-aware modernization is generally safer but more complex to orchestrate.
System intelligence allows DevOps teams to automate safer deployment strategies:
1. Blast-radius-aware rollout plans
2. Automated change risk scoring
3. Closed-loop learning from incidents
The result is DevOps automation that knows what it is touching a precondition for scaling AI-assisted changes without compromising safety.
Example: a simple risk scoring function embedded in CI/CD:
def compute_change_risk(g, changed_nodes):
score = 0
for node in changed_nodes:
data = g.nodes[node]
if data.get("criticality") == "HIGH":
score += 5
if g.out_degree(node) > 10:
score += 3
score += int(data.get("incident_density", 0.0) * 10)
return score
risk = compute_change_risk(g, changed_nodes=["service:billing"])
if risk >= 7:
print("Require canary + manual approval")
elif risk >= 4:
print("Require extended test suite + canary")
else:
print("Standard pipeline")
You can wire this into pipeline logic to select strategies:
deploy_billing:
stage: deploy
script:
- python scripts/compute_risk.py > risk_decision.txt
- ./deploy/strategy_runner.sh "$(cat risk_decision.txt)"
This turns topology and behavior intelligence into concrete rollout policies.
.jpg)
While examples often center around web services, the patterns here apply across industries and technology stacks:
The underlying message is the same: the older and more critical the estate, the more essential it is to construct AI-ready system intelligence before introducing AI-driven automation.
Legacy estates are not just piles of technical debt; they encode decades of business logic, regulatory adaptation, and operational wisdom much of it undocumented. Technical debt becomes truly dangerous when this embedded knowledge can no longer be understood, predicted, or safely modified.
By mining system topology, dependency graphs, data contracts, and behavioral patterns, enterprises can turn hidden logic into a machine-readable asset that underpins safer AI-assisted refactoring, targeted testing, and controlled DevOps automation.
This is what “AI-ready system intelligence for DevOps” really means: not another dashboard or code summarizer, but a continuously updated knowledge graph that balances modernization pressure with operational safety allowing organizations to move from modernization paralysis to informed, incremental transformation across their legacy landscapes.
If you’d like, I can next add concrete architecture diagrams (as Mermaid or PlantUML snippets) and sample code for building the graph ingestion and querying layer, tailored to your preferred stack (e.g., Azure + Databricks + Neo4j).