
Part 2 shows how to implement Golden Asset Records with deterministic and probabilistic matching, mapping tables, pipelines, and governance to link sensors, telematics, and CMMS data for predictive maintenance.
In Part 1, we defined Golden Records for physical assets and outlined core models for asset identity, events, and lifecycle views. In this part, we translate those concepts into concrete data engineering patterns for reconciling OT and IT identifiers at scale.
The focus is pragmatic: given messy historians, SCADA tags, telematics feeds, and CMMS/EAM records, how do you actually build and maintain the mapping from sensor IDs to asset_uid? How do you keep that mapping trustworthy as assets move between projects, lines, and plants?
.jpg)
Think of asset identity resolution as a multi-stage pipeline:
1. Standardize and normalize source fields
2. Apply deterministic matching rules The entity resolution pipeline executes as a two-phase matching architecture a fast deterministic filter followed by a weighted probabilistic scoring stage ensuring that high-confidence mappings are resolved at machine speed while ambiguous candidates are surfaced to engineering review with a fully explainable confidence score rather than silently discarded or incorrectly auto-linked.
The first pass applies aggressive string normalization before any comparison occurs. Serial numbers, equipment codes, and OEM model strings are uppercased, stripped of punctuation and whitespace, and expanded against a reference table of known manufacturer abbreviations and naming variants (e.g., CAT → CATERPILLAR, ABB-M → ABB_MOTOR). Only after normalization is the exact key match executed:
Rows that produce a confirmed exact match are written directly to dim_asset_identifier with match_rule = 'DETERMINISTIC_EXACT' and match_score = 1.0. These records are auto-linked without human review. The remaining unmapped streams those that cleared normalization but produced no exact key match are passed to Phase 2.
For unmapped streams, the pipeline computes a composite confidence score across four weighted dimensions:
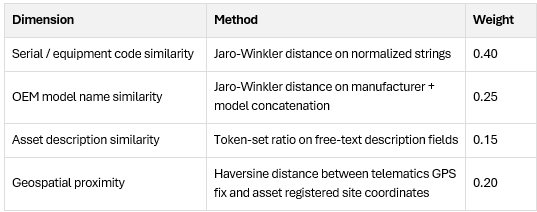
The composite score ScSc for a candidate pair (i,j)(i,j) is computed as:
Sc(i,j)=0.40⋅JW(seriali,serialj)+0.25⋅JW(modeli,modelj)+0.15⋅TR(desci,descj)+0.20⋅G(loci,locj)Sc (i,j)=0.40⋅JW(seriali ,serialj )+0.25⋅JW(modeli ,modelj )+0.15⋅TR(desci ,descj )+0.20⋅G(loci ,locj )
where G(loci,locj)G(loci ,locj ) is a normalized inverse of the Haversine distance, clamped to zero beyond a configurable site radius threshold (default: 500m for fixed plant assets, 5km for mobile construction equipment).
The composite score then drives a three-tier routing decision:
Every candidate pair auto-linked, reviewed, or rejected is persisted in asset_match_rule_execution with its full score vector, the rule version that produced it, and the decided_by field populated by either 'AUTO' or the reviewing engineer's identity. This ensures that any downstream anomaly investigation can trace exactly why a sensor stream was mapped to a specific Golden Asset Record, and what confidence level that mapping carried at the time of the anomaly.
3. Apply probabilistic / fuzzy matching rules (scored, explainable)
When deterministic keys are missing or inconsistent, combine:
4. Human-in-the-loop review for ambiguous cases
This is analogous to customer identity resolution and Golden Records in marketing and identity management platforms, which combine deterministic and probabilistic matching with survivorship rules.
A simple rule table might look like:
CREATE TABLE asset_match_rule_execution (
execution_id BIGSERIAL PRIMARY KEY,
candidate_asset_uid UUID,
system_type VARCHAR(50),
system_name VARCHAR(100),
external_id VARCHAR(255),
match_rule VARCHAR(100), -- SERIAL_EXACT, LOCATION_MODEL_NAME_FUZZY, TAG_PATTERN
match_score DOUBLE PRECISION,
decision VARCHAR(20), -- ACCEPTED, REJECTED, REVIEW_REQUIRED
decided_by VARCHAR(100), -- USER ID or 'AUTO'
decided_at TIMESTAMP
);
This lets you audit why a particular historian tag was mapped to an asset, which is crucial when PdM recommendations start driving automatic work orders and spend.
.jpg)
On modern lakehouse stacks (Databricks, Synapse, BigQuery, Snowflake), a typical pipeline for OT/IT asset ID reconciliation looks like:
1. Raw ingestion layer
2. Standardized staging layer
3. Candidate linking layer
4. Matching & Golden Record layer
5. Served views
A static inner join snapshot is unsuitable as a production identity resolution pattern. OT environments produce late-arriving telemetry metadata continuously a telematics device registration that arrives 6 hours after the first telemetry packet, a historian tag export that reflects a SCADA reconfiguration from 3 days prior, a CMMS equipment master update that was batch-synced overnight. A one-shot join pipeline either misses these arrivals entirely or forces a full table scan across petabytes of historical time-series blocks to reprocess them. The correct pattern is an Incremental Delta Lake Merge Pipeline with watermarked stateful streaming operators that absorb late metadata arrivals and surgically upsert only the affected mapping rows without touching the historical measurement partitions.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit, udf, current_timestamp, expr, coalesce
from pyspark.sql.types import StringType, DoubleType
from delta.tables import DeltaTable
spark = SparkSession.builder.getOrCreate()
#UDFs: Normalization and Scoring
@udf(StringType())
def normalize_serial(s):
"""Strip punctuation, whitespace, uppercase — deterministic normalization."""
import re
if s is None:
return None
return re.sub(r'[^A-Z0-9]', '', s.upper().strip())
@udf(DoubleType())
def jaro_winkler_score(a, b):
"""Jaro-Winkler distance for probabilistic text similarity."""
from jellyfish import jaro_winkler_similarity
if a is None or b is None:
return 0.0
return float(jaro_winkler_similarity(a, b))
@udf(DoubleType())
def geospatial_score(lat1, lon1, lat2, lon2, asset_type):
"""Normalized inverse Haversine distance.
Radius threshold: 500m for fixed plant, 5km for mobile construction.
"""
from math import radians, sin, cos, sqrt, atan2
if any(v is None for v in [lat1, lon1, lat2, lon2]):
return 0.0
R = 6371000
phi1, phi2 = radians(lat1), radians(lat2)
dphi = radians(lat2 - lat1)
dlam = radians(lon2 - lon1)
a = sin(dphi/2)**2 + cos(phi1) * cos(phi2) * sin(dlam/2)**2
dist_m = R * 2 * atan2(sqrt(a), sqrt(1 - a))
threshold = 5000.0 if asset_type == 'MOBILE' else 500.0
return float(max(0.0, 1.0 - (dist_m / threshold)))
# ─────────────────────────────────────────────
# PHASE 1 — Watermarked Streaming Ingest
# Late-arriving metadata handled via event-time watermark
# ─────────────────────────────────────────────
# Read incoming OT identifier metadata as a streaming source
# Source: Kafka topic / Delta Change Data Feed from staging tables
raw_ot_stream = (
spark.readStream
.format("delta")
.option("readChangeFeed", "true") # CDC from bronze staging
.option("startingVersion", "latest")
.table("bronze.stg_ot_identifiers")
.withWatermark("source_event_ts", "72 hours") # tolerate up to 72h late arrivals
)
cmms_master = spark.table("silver.dim_asset").cache()
# ─────────────────────────────────────────────
# PHASE 2 — Deterministic Fast-Pass (Serial Exact Match)
# ─────────────────────────────────────────────
ot_norm = raw_ot_stream.withColumn(
"serial_norm", normalize_serial(col("equipment_serial"))
).withColumn("ingested_at", current_timestamp())
cmms_norm = cmms_master.withColumn(
"serial_norm", normalize_serial(col("oem_serial_number"))
)
# Deterministic join: serial_norm + site_id as compound blocking key
det_matches = (
ot_norm.alias("ot")
.join(cmms_norm.alias("c"), ["serial_norm", "site_id"], "inner")
.select(
col("ot.asset_uid_candidate"),
col("c.asset_uid"),
col("ot.system_type"),
col("ot.system_name"),
col("ot.external_id"),
col("ot.source_event_ts").alias("valid_from"),
lit(None).cast("timestamp").alias("valid_to"),
current_timestamp().alias("system_asserted_at"),
lit(None).cast("timestamp").alias("system_retracted_at"),
lit("DETERMINISTIC_EXACT").alias("match_rule"),
lit(1.0).alias("match_score"),
lit("AUTO").alias("decided_by"),
lit("ACCEPTED").alias("decision")
)
)
# ─────────────────────────────────────────────
# PHASE 3 — Probabilistic Scoring for Unmatched Streams
# Weighted matrix: Jaro-Winkler + Geospatial
# ─────────────────────────────────────────────
unmatched = ot_norm.join(
det_matches.select("external_id"),
["external_id"],
"left_anti"
)
candidates = (
unmatched.alias("ot")
.join(cmms_norm.alias("c"), "site_id", "inner")
)
scored = (
candidates
.withColumn("jw_serial", jaro_winkler_score(col("ot.serial_norm"), col("c.serial_norm")))
.withColumn("jw_model", jaro_winkler_score(col("ot.oem_model_norm"), col("c.oem_model_norm")))
.withColumn("geo_score", geospatial_score(
col("ot.gps_lat"),
col("ot.gps_lon"),
col("c.site_lat"),
col("c.site_lon"),
col("c.asset_type")
))
.withColumn("composite_score",
(col("jw_serial") * lit(0.40)) +
(col("jw_model") * lit(0.25)) +
(lit(0.0) * lit(0.15)) + # desc similarity: extendable
(col("geo_score") * lit(0.20))
)
.withColumn("rank", expr(
"row_number() OVER (PARTITION BY ot.external_id ORDER BY composite_score DESC)"
))
.filter(col("rank") == 1)
.withColumn("decision", expr("""
CASE
WHEN composite_score >= 0.92 THEN 'ACCEPTED'
WHEN composite_score >= 0.72 THEN 'REVIEW_REQUIRED'
ELSE 'REJECTED'
END
"""))
.withColumn("decided_by", expr("""
CASE
WHEN composite_score >= 0.92 THEN 'AUTO'
ELSE 'PENDING_ENGINEER'
END
"""))
.withColumn("match_rule", lit("PROBABILISTIC_WEIGHTED"))
.withColumn("system_asserted_at", current_timestamp())
)
# ─────────────────────────────────────────────
# PHASE 4 — Incremental Delta Merge (UPSERT)
# No full table scan — merge touches only affected asset_uid partitions
# ─────────────────────────────────────────────
def merge_to_mapping_table(batch_df, batch_id):
"""Stateful foreachBatch handler.
Executes a MERGE into dim_asset_identifier using the composite key.
Late-arriving corrections retract the prior row (set system_retracted_at)
and insert the corrected version, preserving full bitemporal history.
"""
mapping_table = DeltaTable.forName(spark, "silver.dim_asset_identifier")
mapping_table.alias("target").merge(
batch_df.alias("source"),
"""
target.asset_uid = source.asset_uid AND
target.system_type = source.system_type AND
target.system_name = source.system_name AND
target.external_id = source.external_id AND
target.valid_from = source.valid_from AND
target.system_retracted_at IS NULL
"""
).whenMatchedUpdate(
condition="source.match_score > target.match_score",
set={"system_retracted_at": current_timestamp()}
).whenNotMatchedInsertAll().execute()
batch_df.write.format("delta").mode("append").saveAsTable(
"silver.asset_match_rule_execution"
)
# ─────────────────────────────────────────────
# PHASE 5 — Streaming Write with Checkpointing
# ─────────────────────────────────────────────
all_resolved = det_matches.unionByName(scored, allowMissingColumns=True)
(
all_resolved.writeStream
.format("delta")
.foreachBatch(merge_to_mapping_table)
.option("checkpointLocation", "/mnt/checkpoints/asset_identity_resolution")
.option("maxFilesPerTrigger", 512) # bounded micro-batch size
.trigger(processingTime="2 minutes") # 2-min micro-batch cadence
.start()
)
The foreachBatch handler is the critical architectural element. Rather than reprocessing the entire dim_asset_identifier table, the MERGE statement is predicated on the composite key (asset_uid, system_type, system_name, external_id, valid_from) with an additional system_retracted_at IS NULL guard ensuring the merge engine touches only the currently asserted, non-retracted rows in the affected asset partitions. When a late-arriving telemetry metadata record carries a higher match_score than the previously asserted mapping, the MERGE retracts the stale row by setting system_retracted_at = current_timestamp() and inserts the corrected version as a new bitemporal row preserving full evidentiary history without overwriting it.
The 72-hour watermark on source_event_ts defines the late-arrival tolerance window: any metadata record arriving within 72 hours of its originating event timestamp is guaranteed to be processed by the stateful streaming operator and correctly merged into the mapping table. Records arriving beyond the watermark boundary are routed to a dead-letter partition in Bronze for manual triage, rather than silently dropped. The 2-minute micro-batch trigger with maxFilesPerTrigger = 512 keeps per-batch MERGE scope bounded, preventing any single late-arrival storm from producing a runaway merge operation across unbounded partition ranges.
.jpg)
In OT, sensors are usually addressed by:
These are often semi-structured strings encoding line, area, equipment, and measurement type. For example:
In CMMS, the same equipment might be P-1007 or CRN-002, with no explicit link to historian tags. The data engineering task is to build robust parsing and pattern-matching functions that extract equipment codes and roles from tag names and map them to CMMS assets.
A practical approach:
1. Regex-based tag parsers
Every extraction attempt accepted or rejected is written to asset_match_rule_execution with the full token sequence, grammar version, and validation outcome, ensuring a complete audit trail for every signal-to-asset mapping decision.
2. Mapping tables for code translations
These mappings can be persisted in dedicated tables
CREATE TABLE dim_signal (
signal_uid UUID PRIMARY KEY,
asset_uid UUID REFERENCES dim_asset(asset_uid),
signal_name VARCHAR(100), -- bearing_temp, oil_pressure
measurement_type VARCHAR(100), -- vibration_rms, temperature, pressure
unit VARCHAR(50),
source_system VARCHAR(100),
external_tag_id VARCHAR(255), -- original tag name or ID
valid_from TIMESTAMP,
valid_to TIMESTAMP
);
Once you have signal_uid and asset_uid consistently mapped, PdM models can:
While relational models are excellent for storage and analytics, a knowledge graph can significantly improve flexibility and queryability of asset relationships and mappings, especially when dealing with many-to-many relationships and complex contexts.
A high-level node-edge enumeration understates what the graph layer must actually do in a production industrial asset intelligence system. The correct framing is an Ontology Graph a formally typed, semantically constrained schema where node labels, relationship types, and property contracts are defined up front, enabling reliability engineers to execute recursive graph traversals that surface transitive dependencies invisible to any relational query model.
Industrial Asset Ontology Schema : Neo4j Cypher Convention
// ─────────────────────────────────────────────
// NODE DEFINITIONS
// ─────────────────────────────────────────────
// Immutable physical asset node — write-once properties only
CREATE CONSTRAINT asset_uid_unique IF NOT EXISTS
FOR (a:Asset) REQUIRE a.asset_uid IS UNIQUE;
(:Asset {
asset_uid: STRING, // system-agnostic stable identifier
oem_model: STRING,
oem_serial_number: STRING,
manufacturer: STRING,
asset_type: STRING, // PUMP | CRANE | COMPRESSOR | CNC | EXCAVATOR
commissioning_date: DATE,
lifecycle_state: STRING // Commissioned | InService | UnderRepair | Retired
})
// Component node — sub-asset physical parts with independent failure modes
(:Component {
component_uid: STRING,
component_type: STRING, // BEARING | HYDRAULIC_VALVE | GEARBOX | ACTUATOR
oem_part_number: STRING,
install_date: DATE,
lifecycle_state: STRING
})
// Measurement signal node — resolved from dim_signal
(:Signal {
signal_uid: STRING,
signal_name: STRING, // bearing_temp | oil_pressure | hyd_valve_flow
measurement_type: STRING,
unit: STRING,
source_system: STRING
})
// System identifier node — OT/IT external IDs
(:SystemIdentifier {
external_id: STRING,
system_type: STRING, // PLC | HISTORIAN | CMMS | TELEMATIC | ERP
system_name: STRING,
valid_from: DATETIME,
valid_to: DATETIME, // NULL = currently active
system_asserted_at: DATETIME
})
// Fault code node — discrete diagnostic events from OBD/telematics/SCADA alarms
(:FaultCode {
fault_uid: STRING,
fault_code: STRING, // OEM DTC or SCADA alarm code
severity: STRING, // CRITICAL | WARNING | INFO
fault_domain: STRING, // HYDRAULIC | MECHANICAL | ELECTRICAL | THERMAL
description: STRING
})
// Operational context nodes
(:Site { site_id: STRING, site_name: STRING, site_type: STRING })
(:Area { area_id: STRING, area_name: STRING })
(:Line { line_id: STRING, line_name: STRING })
// ─────────────────────────────────────────────
// RELATIONSHIP DEFINITIONS WITH PROPERTY CONTRACTS
// ─────────────────────────────────────────────
// Asset → Component: physical containment with temporal validity
(:Asset)-[:HAS_COMPONENT {
install_date: DATE,
removal_date: DATE, // NULL = currently installed
install_work_order_id: STRING,
source_authority: STRING // CMMS | OEM_MANUAL
}]->(:Component)
// Component → FaultCode: known failure mode linkage (ontology-level, not event-level)
(:Component)-[:KNOWN_FAULT_MODE {
propagation_type: STRING, // DIRECT | TRANSITIVE | CONDITIONAL
propagation_delay: DURATION, // expected lag before upstream effect manifests
confidence: FLOAT // 0.0–1.0 based on OEM failure mode data
}]->(:FaultCode)
// FaultCode → FaultCode: transitive failure propagation chain
(:FaultCode)-[:PROPAGATES_TO {
propagation_type: STRING, // CAUSAL | CORRELATED | CONDITIONAL
mean_delay_minutes: INTEGER,
evidence_source: STRING // OEM_FMEA | HISTORICAL_INCIDENT | ENGINEER_DEFINED
}]->(:FaultCode)
// Asset → FaultCode: direct asset-level fault associations
(:Asset)-[:SUSCEPTIBLE_TO {
criticality: STRING // CRITICAL | DEGRADED | MINOR
}]->(:FaultCode)
// Asset → Signal
(:Asset)-[:HAS_SIGNAL {
valid_from: DATETIME,
valid_to: DATETIME
}]->(:Signal)
// Component → Signal: component-level signal ownership
(:Component)-[:MEASURED_BY]->(:Signal)
// Asset → SystemIdentifier: bitemporal external ID mapping
(:Asset)-[:HAS_IDENTIFIER {
valid_from: DATETIME,
valid_to: DATETIME,
system_asserted_at: DATETIME,
system_retracted_at: DATETIME,
source_authority_weight: STRING
}]->(:SystemIdentifier)
// Asset → Operational context: time-bound location edges
(:Asset)-[:DEPLOYED_AT {
valid_from: DATETIME,
valid_to: DATETIME,
deployment_role: STRING // BATCH_MIXER_LINE1 | TOWER_CRANE_ZONE_C
}]->(:Site)-[:CONTAINS]->(:Area)-[:CONTAINS]->(:Line)
The ontology's PROPAGATES_TO relationship between FaultCode nodes is what enables reliability engineers to execute recursive upstream impact queries surfacing transitive dependencies that no flat schema can express. A fault code detected on an auxiliary hydraulic valve component does not exist in isolation: through the ontology graph, the pipeline can traverse the full propagation chain to determine whether that fault state is a known causal precursor to a critical failure state on the parent mechanical engine asset:
// Recursive traversal: from auxiliary hydraulic valve fault → upstream asset failure state
// Finds all transitive propagation paths up to 5 hops deep
MATCH path = (trigger:FaultCode {fault_code: 'HYD-VALVE-FLOW-LOW'})
-[:PROPAGATES_TO*1..5 {propagation_type: 'CAUSAL'}]->
(upstream:FaultCode {severity: 'CRITICAL'})
// Resolve which assets are susceptible to the upstream critical fault
WITH path, upstream
MATCH (a:Asset)-[:SUSCEPTIBLE_TO]->(upstream)
MATCH (a)-[:HAS_COMPONENT]->(c:Component)-[:KNOWN_FAULT_MODE]->(trigger)
// Filter: component must be currently installed (removal_date IS NULL)
WHERE NOT EXISTS {
MATCH (a)-[r:HAS_COMPONENT]->(c) WHERE r.removal_date IS NOT NULL
}
// Surface the full propagation chain with timing context
RETURN
a.asset_uid AS asset_uid,
a.asset_type AS asset_type,
c.component_type AS triggering_component,
trigger.fault_code AS trigger_fault,
upstream.fault_code AS critical_upstream_fault,
upstream.fault_domain AS failure_domain,
reduce(delay = 0, r IN relationships(path) |
delay + r.mean_delay_minutes) AS total_propagation_delay_minutes,
length(path) AS propagation_hops
ORDER BY total_propagation_delay_minutes ASC This query surfaces every asset in the fleet where a currently installed auxiliary hydraulic valve component carries a known HYD-VALVE-FLOW-LOW fault mode that propagates within 5 causal hops to a CRITICAL upstream fault state on the main mechanical engine, along with the expected total propagation delay in minutes. A PdM anomaly scoring engine that detects early hydraulic flow degradation can call this traversal in real time, immediately resolving not just the component-level anomaly but the full upstream asset criticality chain converting a low-severity sensor signal into a prioritized, topology-aware maintenance trigger before the cascading failure state manifests.
PdM only creates value when insights trigger actions in operational systems: work orders, planning changes, safety interventions. CMMS integration guides emphasize mapping fields and aligning asset IDs as core prerequisites for useful automation, not optional niceties.
Once your Golden Asset Record is in place, you can:
.jpg)
A typical automated PdM→CMMS flow:
Pseudocode for the integration lookup:
SELECT external_id AS cmms_equipment_id
FROM dim_asset_identifier
WHERE asset_uid = :asset_uid
AND system_type = 'CMMS'
AND system_name = 'SAP_PM'
AND (valid_to IS NULL OR valid_to > NOW())
ORDER BY is_primary DESC
LIMIT 1; This pattern ensures that as CMMS or EAM systems evolve, your PdM stack continues to function without retraining models or rebuilding pipelines.
The underlying data engineering patterns are the same across construction and manufacturing, but the OT sources and contexts differ.
In construction:
In manufacturing:
In both domains, unified asset intelligence via Golden Records is the enabler that lets PdM systems speak the language of business systems and not just the language of sensors.
Because asset identity is so foundational, it needs explicit governance:
The onboarding contract enforces four mandatory declaration domains:
The contract is enforced by a stateless Asset Identity Gateway at the Bronze ingestion boundary. Non-compliant payloads are not silently dropped they are quarantined to bronze.onboarding_quarantine with the full violation manifest attached, triggering an alert to the reliability engineering team. A stream blocked at the gateway produces zero rows in any downstream Silver or Gold table until its onboarding contract is satisfied ensuring every signal in the production environment is traceable to an authorized, schema-validated Golden Asset Record from the moment of its first byte.
These governance elements are what keep the ID reconciliation effort from decaying back into chaos as the system landscape evolves.
Unified Asset Intelligence is the missing substrate beneath many struggling predictive maintenance programs. The industry has proven that PdM can significantly improve uptime, extend asset life, and reduce maintenance costs in both manufacturing and construction when built on well-contextualized data. But those gains depend critically on having a Golden Record for each physical asset and robust, auditable mappings between OT identifiers, telematics streams, and IT asset masters.
By treating asset identity as a first-class data product complete with deterministic and probabilistic matching rules, lifecycle-aware schemas, knowledge graph representations, and tight integration back into CMMS, EAM, and project controls you create a stable foundation for predictive maintenance models and operational analytics that can survive system migrations and organizational change.
This two-part series has outlined both the conceptual foundations and practical implementation patterns. From here, you can adapt the schemas, pipelines, and governance models to your specific tech stack whether you are orchestrating cranes and excavators across global construction projects or stabilizing uptime in multi-plant discrete manufacturing networks.