
This article is a technical architecture guide for enterprise teams planning sovereign AI deployments with on-premise small language models (SLMs) that must guarantee 100% client data privacy, regulatory compliance, and predictable cost/performance at scale.
Enterprises in regulated industries are moving from generic cloud AI APIs to sovereign AI architectures where models, data, and control planes run entirely within their own infrastructure or tightly controlled sovereign clouds. Small Language Models (SLMs) are central to this transition because their parameter scale, memory footprint, and latency profile make them practical to run on-premise or at the edge while still achieving production-grade task performance.
Recent research and industrial benchmarks show that fine-tuned SLMs can match or exceed frontier-class models on a large share of narrow, well-defined tasks such as classification, extraction, and structured routing, often at a fraction of the serving cost. For high-volume workloads, open-weight SLMs deployed on owned hardware frequently reach cost break-even against commercial APIs in a few months, especially for SMEs and mid-size enterprises.
Beyond cost and privacy, sovereign AI with on-premise SLMs delivers a strategic advantage that is often underappreciated at the leadership level: complete model ownership. When enterprises rely on cloud-hosted AI APIs, they are subject to the provider's versioning lifecycle a model version can be deprecated, changed, or discontinued with limited notice, forcing unplanned migration cycles and introducing operational risk. With on-premise open-weight SLMs, the enterprise owns the model weights outright.
They control when and whether a model version is ever retired. This indefinite versioning capability is a direct business continuity win: mission-critical workflows built on a specific model version remain stable, auditable, and reproducible for as long as the business requires, independent of any vendor's roadmap decisions.
This guide describes how KIAA Professional Services approaches sovereign AI with SLMs: defining privacy guarantees, designing on-prem architectures (air-gapped, VPC-isolated, edge-plus-core), establishing task-based benchmark suites, and performing cost–performance analysis to select the right model and hardware tier.
Sovereign AI refers to AI systems where control over models, data, and execution environment remains entirely with the enterprise or jurisdiction, typically to meet regulatory, contractual, or strategic requirements. This includes strict constraints on data egress, dependency on foreign cloud providers, cryptographic control, and the ability to audit and reproduce model behavior over time.
Small Language Models (SLMs) are language models in the roughly 100M–15B parameter range that can be deployed on a single GPU, CPU server, or even edge devices while still delivering acceptable accuracy for targeted use cases. Because of their smaller footprint, SLMs are naturally suited to sovereign AI scenarios where on-premise or edge deployment, predictable latency, and cost control matter more than solving the widest possible class of open-ended problems.
Key properties that make SLMs attractive for sovereign AI initiatives include:
In a sovereign AI context, "100% client privacy" is not a marketing slogan but an architectural constraint that must be enforced at several layers: network, storage, runtime, and governance. On-prem SLM deployments must satisfy requirements such as data residency, air-gapped operation, auditable access control, and encryption in transit and at rest.
Typical privacy and compliance objectives for sovereign SLM deployments include:
On-premise LLM deployment offerings for enterprises commonly emphasize complete data sovereignty, regulatory compliance, and optional air-gapped operation, providing a useful baseline for SLM-focused architectures.
The following technical mechanisms are central in KIAA-style sovereign SLM architectures:
For sovereign deployments, the primary question is not "Which model is best in general?" but "Which model and configuration achieve the required quality, latency, and cost on this specific task under our privacy constraints?" This pushes evaluation away from generic leaderboards toward task-based benchmark suites that reflect real enterprise workloads.
Multiple empirical studies find that fine-tuned SLMs outperform large general-purpose models on most specialized classification and extraction tasks when evaluated in-domain. One study benchmarking 310 fine-tuned models across 31 tasks reported that small fine-tuned models beat a strong general-purpose baseline on roughly 25 of 31 tasks with an average improvement of about 10 percentage points.
Additional work on fine-tuning indexes shows that domain-tuned models often achieve 25–50% relative improvement versus their base variants on specialized workloads, especially when the task is structured (labels, spans, templates) rather than open-ended generation. This suggests that for many sovereign use cases—claims triage, policy routing, entity extraction, risk flags—SLMs can be the primary workhorse, with larger models reserved for rare, escalated cases.
A robust benchmark suite for SLM selection and tuning should be:
For SLM-centric deployments, additional metrics such as fine-tuning speed, adaptation efficiency, and real-time inference performance on constrained hardware are important, as they directly impact operational viability.
Common categories in KIAA-style benchmark harnesses include:
In each category, SLMs are evaluated side-by-side with larger models (where permitted) under identical constraints and prompt templates, enabling objective task-based decisions without relying on generic benchmark rankings.
SLM-based sovereign AI systems can be instantiated in several architectural patterns depending on regulatory constraints, latency requirements, and scale. Their smaller resource footprint enables patterns that are impractical for very large models, particularly in edge and air-gapped environments.
Most enterprise SLM architectures share the following components:
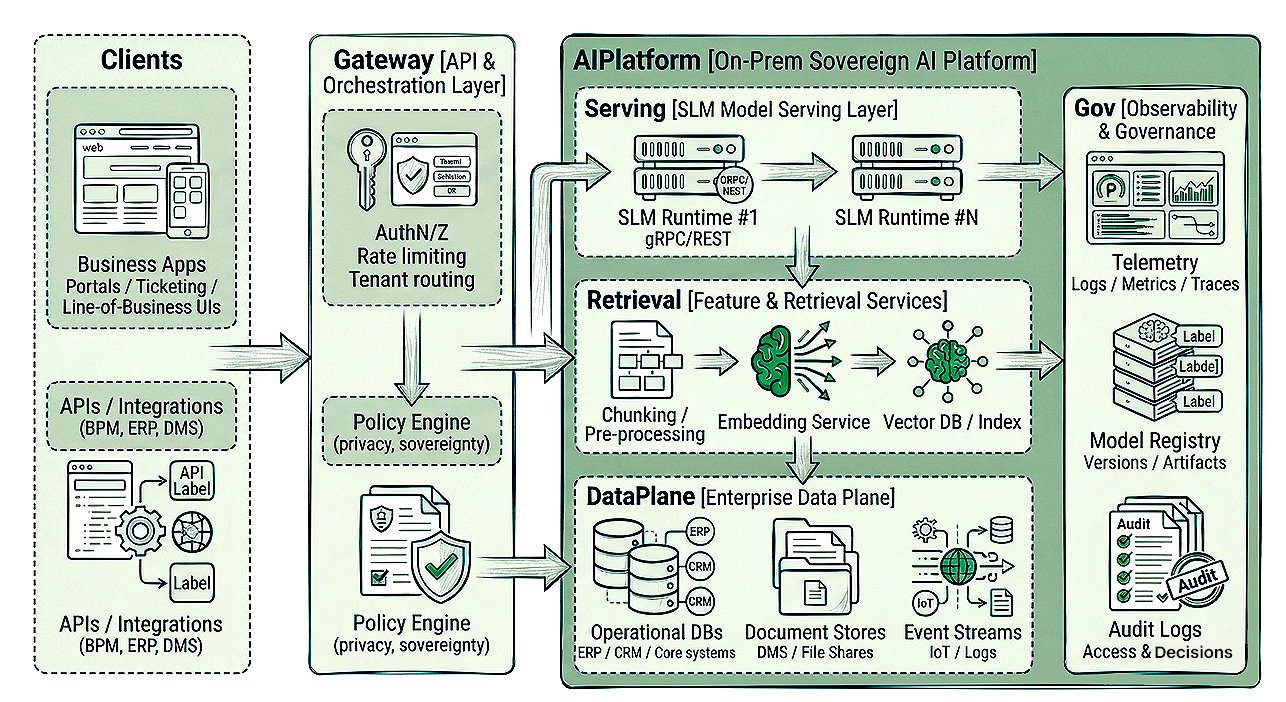
These building blocks can be arranged into different deployment topologies while preserving the sovereignty guarantees.
In the strictest environments (defense, critical infrastructure, high-sensitivity financial workloads), each client or business unit may operate an air-gapped cluster:

On-prem LLM deployment providers describe similar setups where clusters are fully contained within the enterprise perimeter, enabling complete data sovereignty and regulatory compliance.
SLMs reduce hardware requirements in such environments, because a single node with a high-memory GPU can handle many concurrent tasks.
For B2B SaaS platforms or shared enterprise services, a multi-tenant architecture is more efficient:
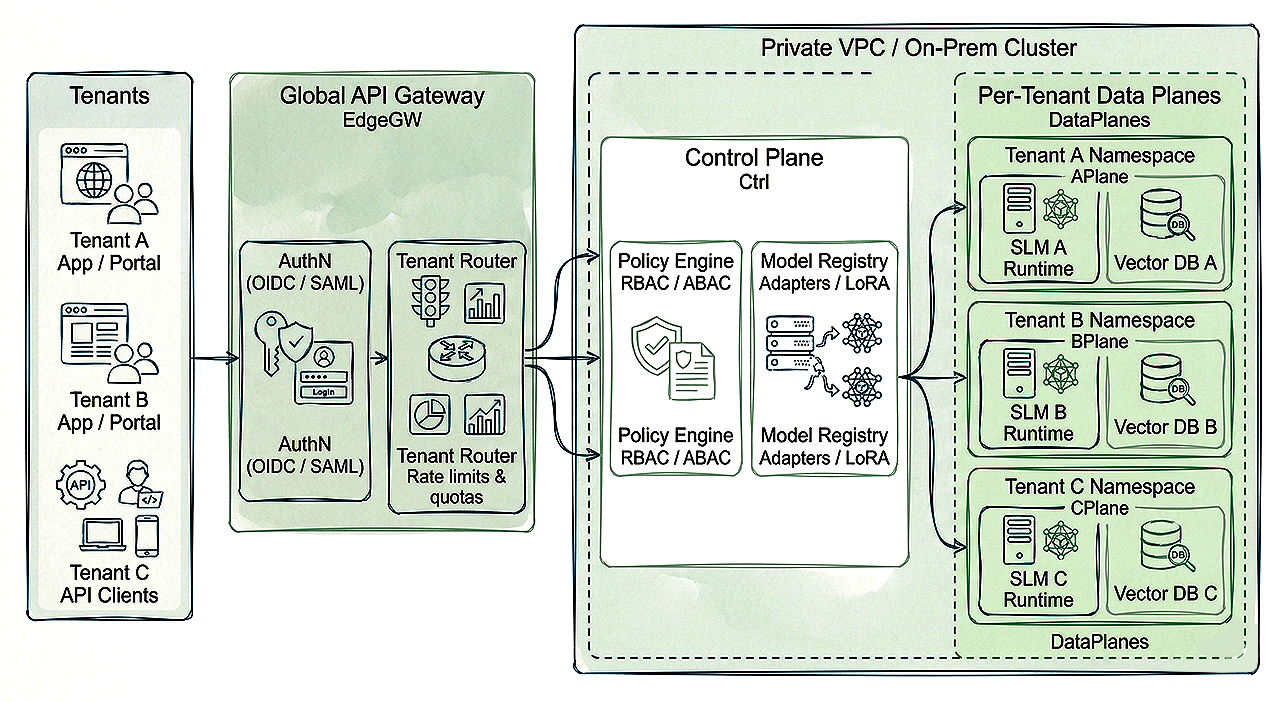
Because SLMs require less memory and compute, per-tenant specialization is feasible while retaining high throughput on a moderate number of GPUs or even CPU-only servers for lighter workloads.
Edge-first architectures place SLMs directly on endpoint or near-edge devices for real-time, low-latency processing, with optional fallback to larger core models.
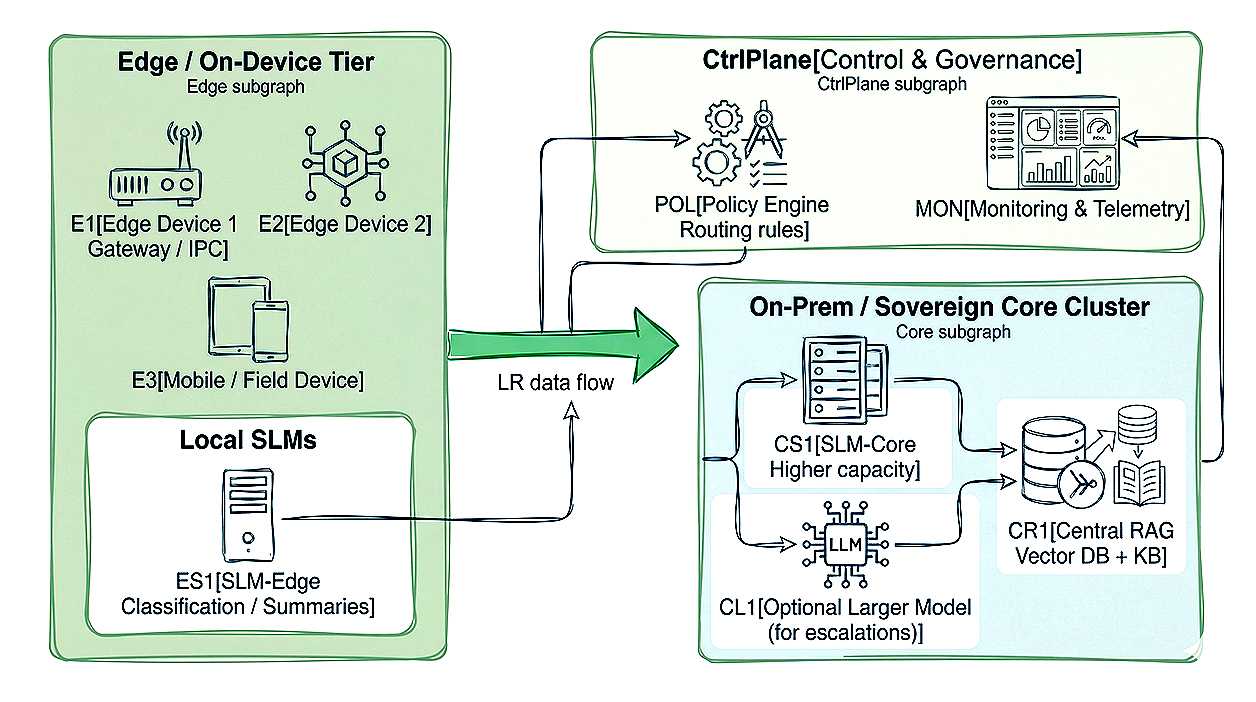
Research on edge SLM inference demonstrates that on-device models can achieve competitive response quality for many tasks while drastically reducing latency, bandwidth consumption, and sometimes overall cost per request. Edge clusters can then escalate only complex or ambiguous cases to central on-prem or sovereign-cloud instances, balancing resource use against quality.
In this pattern:
Choosing SLMs for sovereign AI is ultimately an economic as well as technical decision. Enterprises must weigh hardware and operational costs of on-prem deployments against per-token pricing of external APIs, under the constraint that sensitive data may never leave their control.
Cost–benefit analyses of on-prem language model deployments show that small and medium-size open-weight models can often be deployed on relatively affordable hardware such as high-end consumer or workstation GPUs while still delivering acceptable throughput. Studies highlight that models in the sub-30B parameter range (including "small" and "medium" categories) are feasible on single modern GPUs and can serve a wide range of enterprise workloads.
These analyses further indicate that for many organizations, especially SMEs with continuous workloads, the break-even point versus commercial API usage can occur within 0.3–3 months, depending on query volume and the baseline provider. When combined with the privacy and sovereignty benefits of keeping data entirely in-house, SLM-based on-prem deployments become attractive even before purely financial parity is reached.
The economic case is further reinforced by an ESG dimension that is increasingly material for enterprise leadership. Running an SLM on a single on-premise GPU node consumes a fraction of the energy compared to routing equivalent workloads through large-scale cloud data centres, which run hyperscale GPU clusters across multiple regions with significant cooling and infrastructure overhead.
For high-volume, repetitive tasks classification, extraction, triage :where an SLM delivers comparable accuracy, the per-query carbon footprint of on-prem inference is measurably lower. For enterprises with board-level ESG commitments or regulatory sustainability reporting obligations (such as BRSR in India or CSRD in the EU), this makes sovereign SLM deployments a direct contributor to carbon reduction targets :not merely an IT efficiency initiative, but a sustainability strategy with quantifiable Scope 2 emission benefits
Performance evaluation for SLM deployments must consider not only accuracy but also latency, throughput, energy use, and cost per request:
A structured evaluation using these metrics allows decision-makers to choose between:
Guides comparing SLMs and large models emphasize that model size should be aligned to task complexity, latency requirements, and budget.
SLMs are typically optimal for:
Larger models may still be justified for:
Within sovereign AI programs, this often leads to a two-tier pattern: SLMs as the default engine for most traffic, with a more capable but tightly controlled model reserved for specialist flows that justify additional complexity and cost.
KIAA Professional Services uses a structured lifecycle for designing and delivering sovereign AI platforms anchored on SLMs. This lifecycle combines architecture, security, MLOps, and domain-specific modeling in a repeatable pattern aligned to enterprise governance.
In the initial phase, the focus is on aligning business priorities, regulatory constraints, and technical readiness:

Next, KIAA typically runs a PoC that implements the full task-based benchmarking approach described earlier:
External deployment guides for SLMs recommend similar progression: start small, validate impact via PoC, then invest in more robust infrastructure and integration once the benefits are proven.
Once PoC success criteria are met, KIAA designs and implements a production-grade architecture selecting one of the patterns described in Section 4:
At this stage, hardware investments may scale from a single-node PoC to multi-GPU servers (such as A100-class) or clusters, depending on volume and latency demands.
Finally, KIAA establishes an operational framework around the SLM platform:
This lifecycle ensures that sovereign SLM deployments evolve predictably while maintaining the original privacy and compliance guarantees.
Right-sizing hardware is critical to achieving the intended cost–performance benefits of on-prem SLM deployments. Because SLMs have a smaller memory and compute footprint, more flexible hardware choices become available compared to very large models.
Practical deployment guides suggest a staged approach:
Studies on small model deployment economics report that even smaller open models up to about 30B parameters can be hosted on modern single GPUs like RTX 5090, further widening the feasible range of on-prem deployments for SMEs and mid-size enterprises.
For edge-centric use cases, SLMs can run on industrial PCs, gateways, or even mobile devices:
Capacity planning for SLM-based sovereign AI platforms should consider:
Using integrated metrics such as CPR and PCR from edge SLM research, architects can simulate different configurations (CPU-only clusters, mixed GPU tiers, edge-plus-core hybrids) before committing to hardware investments.
Industry research and enterprise deployment experience converge on a clear pattern: SLMs are central to practical sovereign AI in environments that demand strict privacy and predictable cost.
By focusing evaluation on task-based benchmarks, enforcing strong on-prem privacy controls, and right-sizing hardware, enterprises can deliver high-value AI capabilities entirely within their own infrastructure.
Within this context, the role of the architect is to design reference patterns—air-gapped, multi-tenant, and edge-plus-core—that can be reused across use cases while preserving client privacy and regulatory compliance. KIAA Professional Services formalizes these patterns into a repeatable delivery methodology, enabling organizations to adopt sovereign SLM-based AI with confidence and control.