
Learn how Agentic RAG replaces brittle, static RAG with adaptive, multi-agent AI that delivers reliable, end-to-end enterprise knowledge workflows
Enterprise AI is undergoing a fundamental architectural transformation. Traditional Retrieval-Augmented Generation (RAG) systems, while effective for single-shot query-response workflows, fail to meet the demands of complex, multi-step enterprise operations. Agentic RAG introduces autonomous reasoning, dynamic tool orchestration, and adaptive context management—capabilities that translate directly into measurable business outcomes including 35% conversion rate improvements and 60% reductions in manual compliance work.
In this blog we explore how Agentic RAG fundamentally upgrades traditional RAG by turning static, single-pass pipelines into adaptive, multi-agent AI knowledge systems built for real-world enterprise complexity. Learn how autonomous reasoning, dynamic tool orchestration, and conflict-aware context synthesis reduce hallucinations, resolve ambiguous queries, and deliver trustworthy insights across fragmented CRMs, wikis, tickets, and email systems. See why static, linear RAG architectures break down for multi-step workflows, compliance-heavy processes, and decision-critical operations. Understand the architectural shift from reactive retrieval to proactive research, where AI agents iteratively refine queries, reconcile conflicting sources, and optimize retrieval strategies in real time. Lastly, Discover how this transition unlocks measurable business impact, from higher conversion and faster deal cycles to reduced manual review and lower operational risk in regulated, data-intensive environments.
The distinction between Traditional RAG and Agentic RAG is not a matter of simple improvements—it's a shift between two fundamentally different computational mindsets and architectures:
Traditional enterprise knowledge systems struggle due to three persistent challenges:
1. Context Fragmentation: Critical information is siloed across multiple platforms (e.g., CRMs, wikis, ticketing systems, email), making end-to-end retrieval difficult and error-prone.
2. Query Ambiguity: User inputs are frequently vague, multi-intent, or lacking in necessary detail, leading to ineffective retrieval with traditional static approaches.
3. Information Quality: The data brought back may be outdated, irrelevant, incomplete, or mutually contradictory—resulting in confusion and operational risk.
Traditional RAG offers a partial answer to context fragmentation by surfacing information from one or more knowledge bases. However, it fails to resolve ambiguity and lapses in information quality—there’s no built-in mechanism to clarify intent or validate conflicting sources.
Agentic RAG, by contrast, systematically overcomes all three challenges. It leverages autonomous reasoning to:
This fundamental architectural transition enables Agentic RAG systems to deliver dependable, actionable intelligence in complex enterprise and real-world environments.
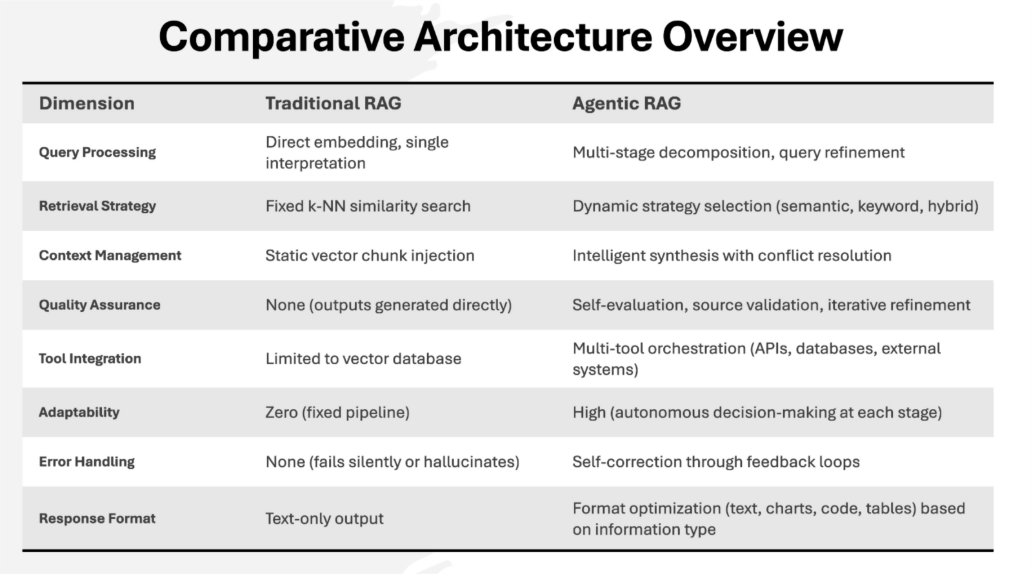
Traditional RAG implements a deterministic, feed-forward architecture where each stage passes results to the next without feedback or adaptation. Understanding this pipeline is essential for recognizing where it thrives and where it fails in enterprise contexts.
The user's query is transformed into a numerical vector through a pre-trained embedding model (e.g., Azure OpenAI's text-embedding-3-large, dimension 1536). This vector exists in a latent space where similarity corresponds to semantic relatedness. The embedding model is frozen during inference—it cannot adapt to domain-specific terminology or query context.
The query vector is compared against vectors stored in a vector database using distance metrics (cosine similarity, Euclidean distance, dot product). The database returns the top-k most similar chunks, typically using approximate nearest neighbor (ANN) algorithms for scalability. This stage is mechanically simple: similarity scores determine retrieval order with no reasoning about relevance.
Retrieved chunks are concatenated into a prompt template, which is sent to the language model for single-pass generation. The LLM receives no information about retrieval confidence, contradictions within the context, or whether the context fully addresses the query. It generates an answer based solely on the assembled prompt.
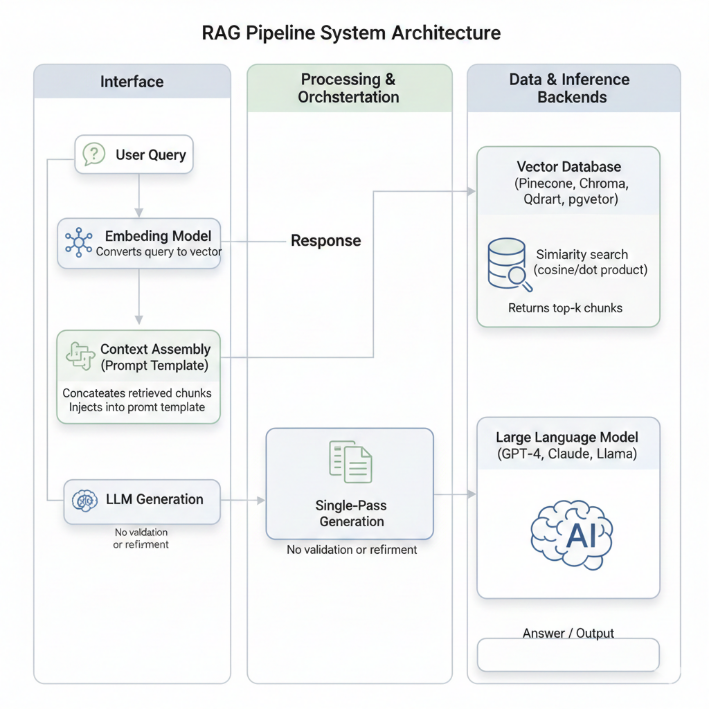
A production Traditional RAG system consists of two distinct phases with different performance characteristics and operational requirements:
1. Document Ingestion: Raw documents (PDFs, Word files, web pages, database exports) are loaded and parsed to extract text.
2. Text Segmentation: Documents are divided into chunks using strategies like fixed-size windows (512 tokens), semantic boundaries (sentence/paragraph breaks), or recursive splitting for hierarchical preservation.
3. Embedding Generation: Each chunk is embedded using the selected embedding model. For large-scale systems, batch processing is critical for cost and latency efficiency. A typical indexing job for 100K documents takes 2-4 hours with batching.
4. Vector Storage: Embeddings and metadata (document ID, chunk index, timestamp, source URL) are persisted in a vector database with appropriate indexing for fast ANN queries.
1. Query Vectorization: Incoming query is embedded in real-time, typically completing within 50-200ms depending on model and infrastructure.
2. Approximate Nearest Neighbor Search: The query vector is compared against stored embeddings. ANN algorithms (HNSW, IVF) return top-k candidates in 10-50ms for million-scale indexes.
3. Context Retrieval and Assembly: Top-k chunks are retrieved, sorted by score, and formatted into the prompt template.
4. LLM Invocation: The augmented prompt is sent to the language model for generation, typically taking 1-3 seconds for moderate-length responses.
Traditional RAG treats all queries as fixed points in semantic space. A query like "What is our remote work policy?" and its variants "Can I work from home?", "Tell me about telecommuting," "Flexible location arrangements" may map to completely different regions of the embedding space, yielding non-overlapping retrieval results. The system has no mechanism to recognize that these formulations express equivalent intent.
Real-world consequence (Financial Services): A compliance query asking "Identify transactions violating sanctions lists" retrieved documents about transaction processing infrastructure rather than sanction policy documents. Switching the query to "Which payments breach OFAC requirements?" returned correct documents. Traditional RAG could not bridge this terminology gap; a compliance officer had to craft the "right" query through trial and error.
The top-k parameter is set at system design time (typically k=5-10 for general QA, k=20-50 for research tasks). There's no intelligence about whether this window is sufficient for a given query's complexity.
Example scenario: A query like "Summarize our Q3 financial performance" might require information from multiple documents (earnings reports, departmental summaries, market analysis). Retrieving k=5 chunks risks fragmented context. Conversely, "What is the office phone number?" needs only k=1. Traditional RAG treats both identically.
The system cannot assess whether retrieved chunks are actually relevant, current, or mutually consistent. If a vector database contains outdated information alongside current information with similar embeddings, Traditional RAG will retrieve both without distinguishing them. Contradictory information in the context confuses the LLM, increasing hallucination risk.
Observational data (Healthcare): A healthcare knowledge system retrieved both the current (2025) medication protocol and an archived (2020) protocol from the same database, as their embeddings were nearly identical. The LLM averaged the recommendations, producing guidance that matched neither current nor historical protocols—increasing adverse event risk.
Most Traditional RAG implementations query one vector database. Enterprise environments have multiple knowledge silos: CRM systems, ERP documentation, wiki pages, customer support tickets, compliance databases, and structured data warehouses. A query requiring insight from multiple sources—e.g., "Why did customer X churn, and which product features could have prevented it?"—cannot be answered by retrieving from a single knowledge base.
Enterprise case (SaaS): A customer success query like "Show me all customer escalations related to billing issues in the EMEA region" requires correlating customer support tickets (one database) with CRM data (another system) with billing transaction logs (a third system). Traditional RAG, querying only the support ticket vector store, could not deliver the cross-system intelligence required.
When multiple chunks are retrieved, Traditional RAG simply concatenates them in similarity-score order. This approach leads to several inefficiencies:
This is particularly problematic in regulated industries. A compliance query retrieving 15 relevant documents might exceed GPT-4's context window. The system truncates without understanding which information is legally critical versus background context.
Despite these limitations, Traditional RAG remains strategically valuable for specific use cases:
1. Well-Defined FAQ and Knowledge Management
Systems with known, discrete queries and authoritative answers excel with Traditional RAG. Internal HR knowledge bases, IT helpdesk systems, and product documentation portals typically have predictable query patterns. Cost is low, operational complexity is minimal, and performance is consistent.
Real implementation (Technology Company): A 500-person company built a Traditional RAG system over their employee handbook, salary grades, benefits guide, and IT policies. The system serves 80% of employee questions correctly. Development time was 6 weeks, operational cost is $200/month, and setup required only two engineers.
2. Narrow-Domain Technical Search
Specialized documentation searches within homogeneous content (API references, code examples, engineering specifications) perform well. The limited semantic variation across similar technical documents means embedding-based retrieval is highly effective.
Example: An API documentation search for "JWT authentication" consistently retrieves the correct reference page because technical content has lower synonym variation than general text.
3. Budget-Constrained Deployment
Traditional RAG's lower computational requirements make it suitable for resource-limited environments. Operating costs (vector database hosting, embedding inference) are 30-50% lower than Agentic RAG.
Startup scenario: Early-stage SaaS platforms often start with Traditional RAG to minimize burn rate while validating market fit. As query complexity increases with customer needs, they migrate to Agentic RAG—but Traditional RAG provides a low-risk entry point.
4. Predictable, Well-Structured Query Patterns
Systems where user queries follow consistent linguistic and semantic patterns (e.g., customer support escalation routing: "I have a question about [TOPIC]") benefit from the simplicity and low overhead of Traditional RAG.
Production deployments of Traditional RAG demonstrate consistent performance profiles across domains:
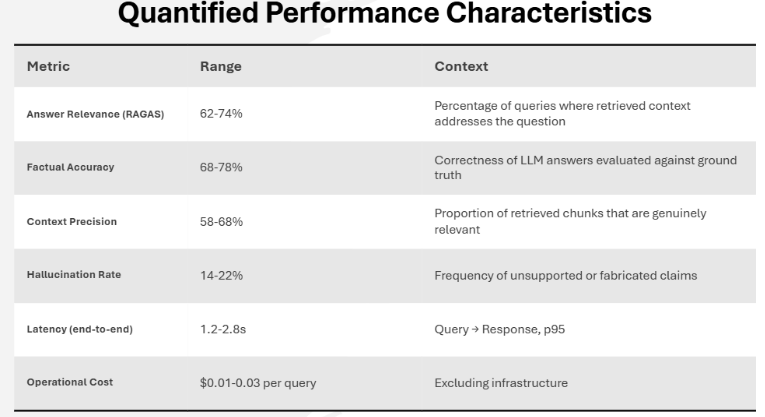
A 70% answer relevance score means 3 out of 10 queries retrieve context that doesn't meaningfully address the question. This 30% miss rate is acceptable for exploratory search but unacceptable for regulatory compliance, financial advice, or healthcare contexts where errors are consequential.
The 16-18% average hallucination rate reflects the LLM generating plausible-sounding but unfounded claims when context is insufficient. For high-stakes decisions, this frequency demands human verification, negating automation benefits.
config/traditional_rag_config.yaml
system:
name: "traditional-rag-system"
environment: "production"
embedding:
provider: "azure_openai"
model: "text-embedding-3-large"
dimensions: 1536
batch_size: 100
vector_store:
provider: "weaviate"
endpoint: "${WEAVIATE_ENDPOINT}"
api_key: "${WEAVIATE_API_KEY}"
index_name: "knowledge_base"
retrieval:
strategy: "similarity_search"
top_k: 8
distance_metric: "cosine"
threshold: 0.0
llm:
provider: "azure_openai"
model: "gpt-4"
temperature: 0.7
max_tokens: 2000
src/traditional_rag/pipeline.py
from typing import Tuple, List
from azure.identity import DefaultAzureCredential
from langchain_openai import AzureOpenAIEmbeddings, AzureChatOpenAI
from langchain_community.vectorstores import Weaviate
from langchain_core.prompts import PromptTemplate import yaml
class TraditionalRAGPipeline: """Three-stage Traditional RAG implementation."""
def __init__(self, config_path: str):
with open(config_path, 'r') as f:
self.config = yaml.safe_load(f)
# Stage 1: Embedding model initialization
self.embeddings = AzureOpenAIEmbeddings(
deployment=self.config['embedding']['model'],
model=self.config['embedding']['model'],
dimensions=self.config['embedding']['dimensions']
)
# Stage 2: Vector database connection
self.vector_store = Weaviate.from_config(
embedding=self.embeddings,
environment_variables={
"WEAVIATE_URL": self.config['vector_store']['endpoint'],
"WEAVIATE_API_KEY": self.config['vector_store']['api_key']
}
)
# Stage 3: LLM initialization
self.llm = AzureChatOpenAI(
deployment_name=self.config['llm']['model'],
model_name=self.config['llm']['model'],
temperature=self.config['llm']['temperature'],
max_tokens=self.config['llm']['max_tokens']
)
# Prompt template
self.prompt_template = PromptTemplate(
input_variables=["context", "query"],
template="""
Answer the following question using only the provided context. If the context doesn't contain information to answer the question, state that clearly.
Context: {context}
Question: {query}
Answer:""" )
def retrieve(self, query: str) -> Tuple[List[str], List[float]]:
"""
Stage 2: Retrieve top-k chunks using similarity search.
Returns chunks and similarity scores.
"""
# Stage 1 (implicit): Query is automatically embedded
results = self.vector_store.similarity_search_with_scores(
query=query,
k=self.config['retrieval']['top_k']
)
chunks = [doc.page_content for doc, _ in results]
scores = [score for _, score in results]
return chunks, scores
def assemble_context(self, chunks: List[str]) -> str:
"""Stage 3a: Concatenate chunks without prioritization."""
return "\n\n".join([
f"[Chunk {i+1}]\n{chunk}"
for i, chunk in enumerate(chunks)
])
def generate(self, query: str, context: str) -> str:
"""Stage 3b: Single-pass LLM generation."""
prompt = self.prompt_template.format(
context=context,
query=query
)
response = self.llm.invoke(prompt)
return response.content
def invoke(self, query: str) -> dict:
"""Execute the three-stage pipeline."""
# Stage 1: Query vectorization (implicit in retrieve)
chunks, scores = self.retrieve(query)
# Stage 2: Context assembly (no validation)
context = self.assemble_context(chunks)
# Stage 3: LLM generation
answer = self.generate(query, context)
return {
"query": query,
"answer": answer,
"retrieved_chunks": chunks,
"retrieval_scores": scores,
"source_count": len(chunks)
}
Example usage
if name == "main": pipeline = TraditionalRAGPipeline("config/traditional_rag_config.yaml")
result = pipeline.invoke(
query="What is our remote work policy?"
)
print(f"Answer: {result['answer']}")
print(f"Sources used: {result['source_count']}")
The above code exemplifies Traditional RAG's simplicity: three distinct stages with no feedback, validation, or adaptation. This simplicity is both its strength (low operational complexity) and its weakness (inability to handle complex scenarios).
Agentic RAG is not just “RAG with more steps”; it is an architectural leap from static retrieval to autonomous, multi-agent reasoning designed for complex enterprise knowledge work.
Agentic RAG introduces a network of specialized AI agents that plan, execute, validate, and refine retrieval strategies instead of running a single, linear query → retrieve → generate pipeline. Each agent operates with its own goals, tools, and decision policies, coordinated through an orchestration layer.
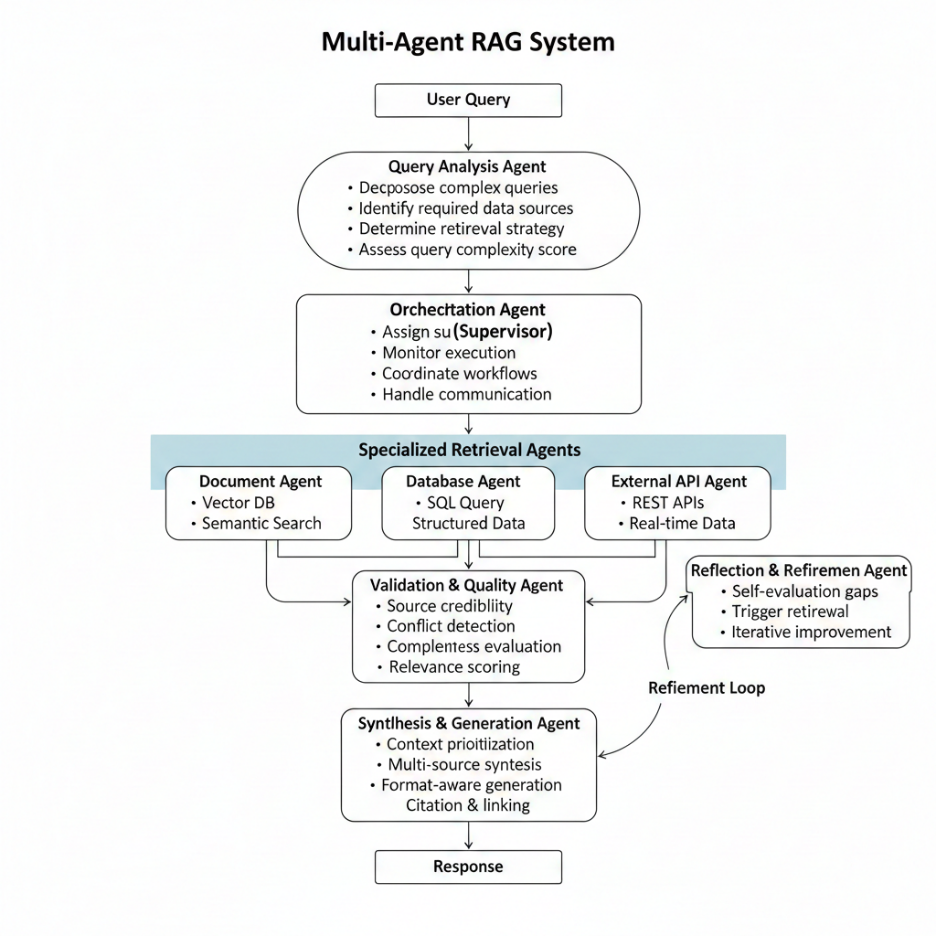
1. User Query → Query Analysis Agent
2. Orchestration (Supervisor) Agent
3. Specialized Retrieval Agents
4. Validation & Quality Agent
5. Synthesis & Generation Agent
6. Reflection & Refinement Agent
The result is a non-linear, adaptive workflow in which agents can branch, revisit earlier steps, and adjust strategies based on intermediate observations—something that static RAG simply cannot do.
Modern Agentic RAG systems typically adopt one of three orchestration patterns that map well to enterprise workloads: sequential (pipeline), parallel (fan-out/fan-in), and hierarchical (supervisor–worker). These patterns are crucial keywords in designing scalable multi-agent and agentic RAG architectures.
In sequential/pipeline orchestration, agents execute in a strict order, each consuming the previous agent’s output.
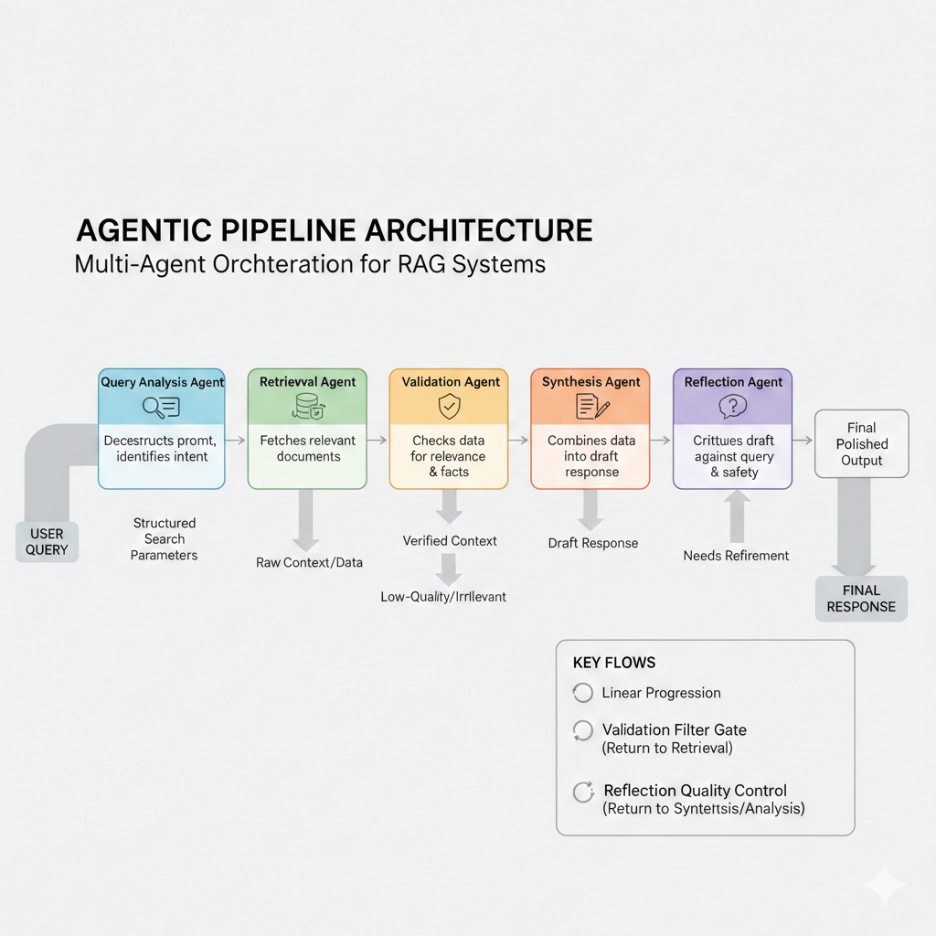
This pattern is well suited when correctness and auditability outweigh latency, especially in regulated industries (finance, healthcare, public sector).
In parallel/fan-out–fan-in orchestration, multiple specialized agents work simultaneously on different aspects of the task, and their outputs are later merged.
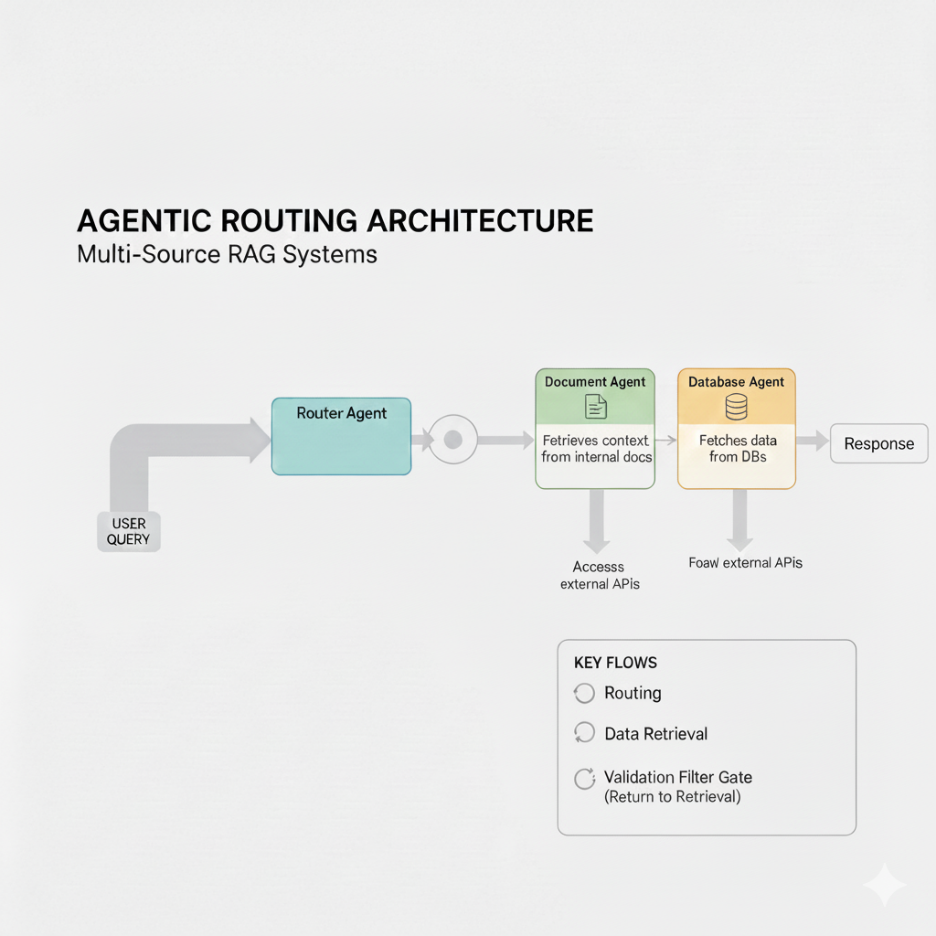
This is the preferred pattern for customer support copilots, SRE/incident copilots, and sales/revenue intelligence copilots, where speed and breadth of coverage matter.
Hierarchical orchestration adds another layer: supervisor agents that manage specialized worker agents, mirroring organizational structures.
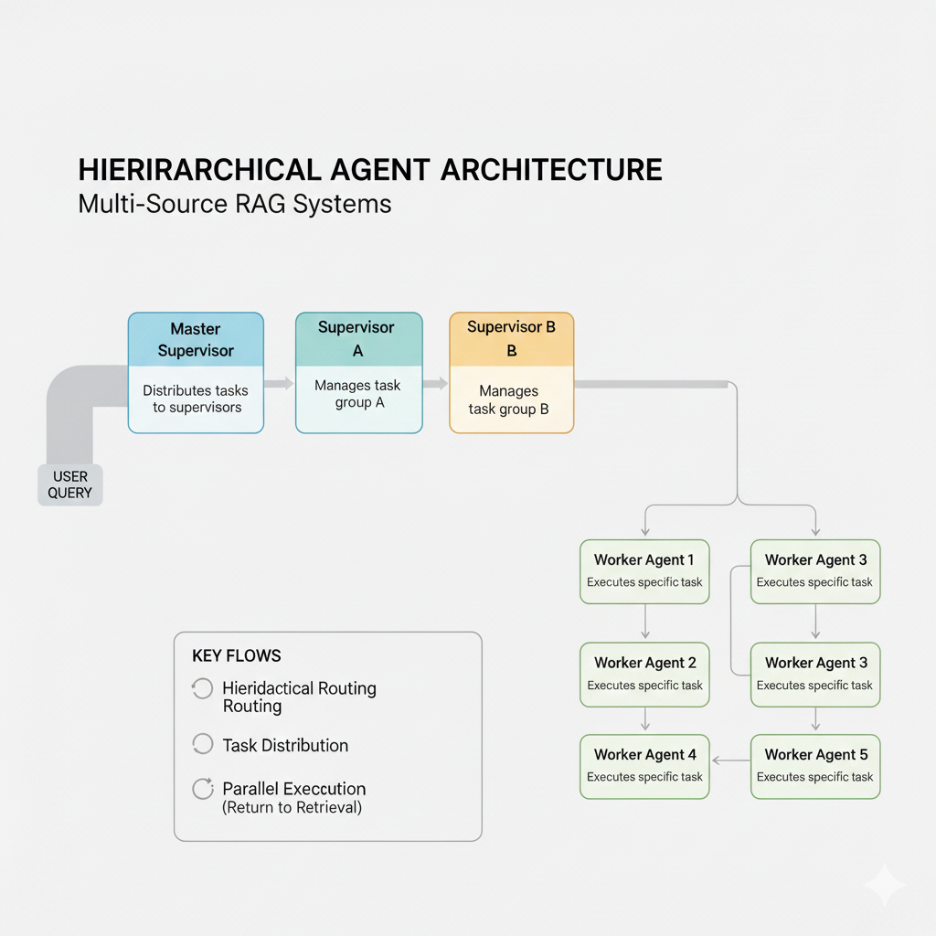
This is the canonical pattern for enterprise-wide AI platforms where a single “front door” copilot can orchestrate across legal, finance, HR, engineering, and operations.
Each agent in an Agentic RAG system is not just a “tool wrapper” but a bounded autonomous system with four core capability layers.
These four layers are core keywords when designing agent frameworks, agentic RAG platforms, and enterprise AI operating models.
A single embedding is computed, and a static similarity search is executed:
query_embedding = embed_model.encode(user_query)
results = vector_db.search(query_embedding, k=5) No intent modeling, no sub-tasks, no source planning.
A Query Analysis Agent converts the user request into a structured query plan:
query_analysis = analysis_agent.process({
"query": user_query,
"context": conversation_history,
"user_profile": user_metadata
})
# Example output
{
"intent": "multi_step_comparison",
"sub_queries": [
"Get current remote work policy",
"Get previous policy revisions",
"Identify key changes over time" ],
"required_sources": ["hr_docs", "policy_archive", "announcement_emails"],
"complexity_score": 7.2,
"expected_format": "comparison_table"
}
Impact:
Retrieval parameters are static:
results = vector_db.search(query_embedding, k=5) Every query gets the same k, same strategy, same source.
Retrieval varies based on complexity, intent, and required coverage:
if query_analysis["complexity_score"] > 7:
strategy = "hierarchical_multi_source"
k = query_analysis["estimated_sources"] * 3
elif query_analysis["intent"] == "factual_lookup":
strategy = "precise_semantic"
k = 2
else:
strategy = "standard_semantic"
k = 5
results = retrieval_agent.execute_strategy(
strategy=strategy,
sources=query_analysis["required_sources"],
k=k
)
Impact:
Whatever is retrieved is blindly injected into the prompt:
context = "\n\n".join(chunk.text for chunk in results)
response = llm.generate(prompt_template.format(context=context, query=user_query)) No checks for conflicts, recency, or completeness.
A Validation & Quality Agent scores and manipulates retrieved content before generation:
validation_results = validation_agent.assess({
"chunks": results,
"query": user_query,
"criteria": ["relevance", "credibility", "recency", "completeness"]
})
if validation_results["conflicts_detected"]:
resolved_context = validation_agent.resolve_conflicts( chunks=results,
strategy="recency_weighted" # or 'source_authority', 'consensus' )
else:
resolved_context = results
if validation_results["completeness_score"] < 0.7: additional_results = retrieval_agent.targeted_search( gaps=validation_results["identified_gaps"]
)
resolved_context.extend(additional_results)
Impact:
One-shot generation; whatever the LLM outputs is final.
response = llm.generate(prompt)
return response
A Reflection & Refinement Agent critiques and improves the answer:
initial_response =
generation_agent.create(context=resolved_context, query=user_query)
evaluation = reflection_agent.evaluate({
"response": initial_response,
"query": user_query,
"context": resolved_context,
"criteria": ["accuracy", "completeness", "clarity", "citation_quality"]
})
iteration_count = 0
while evaluation["overall_score"] < 0.85 and iteration_count < 3: improvements =
reflection_agent.suggest_improvements(evaluation)
if "insufficient_context" in improvements:
additional_context = retrieval_agent.targeted_search(
gaps=improvements["missing_aspects"]
)
resolved_context.extend(additional_context)
refined_response = generation_agent.refine( previous_response=initial_response, improvements=improvements, context=resolved_context
)
evaluation = reflection_agent.evaluate({
"response": refined_response,
"query": user_query,
"context": resolved_context,
"criteria": ["accuracy", "completeness", "clarity", "citation_quality"]
})
initial_response = refined_response iteration_count += 1
final_response = initial_response
Impact:
The distinction between Traditional RAG and Agentic RAG is not academic. It reflects a fundamental recognition that enterprise AI systems must evolve from passive information retrievers to proactive, reasoning-driven knowledge workers capable of handling ambiguity, complexity, and consequence.
Traditional RAG represents a significant step forward from unaugmented LLMs—it grounds responses in actual enterprise data and reduces hallucination risk. For narrow, well-defined use cases (FAQ systems, technical documentation search, FAQ portals), it delivers substantial value at low operational cost. Organizations starting their AI journey can, and should, begin here.
However, as enterprise AI matures beyond pilots into production workloads spanning compliance, customer operations, strategic decision-making, and cross-system integration, Traditional RAG's architectural limits become business constraints:
These limitations are not engineering failures—they are architectural constraints of a linear, static paradigm.
Agentic RAG addresses these constraints through four foundational shifts:
1. Query Intelligence: Ambiguous user requests are decomposed into explicit, machine-executable plans, eliminating the "right query formulation" guessing game.
2. Adaptive Strategy: Retrieval methods, source selection, and aggregation logic vary per query based on complexity and intent, optimizing cost and quality simultaneously.
3. Quality Validation: Retrieved information is scored for credibility, temporal relevance, and consistency before generation. Conflicts are resolved explicitly rather than left for the LLM to average.
4. Iterative Refinement: Responses are self-evaluated against domain-specific criteria and improved through targeted retrieval and regeneration, converging toward higher-quality outputs without manual intervention.
The ROI case is compelling:
Financial services, healthcare, SaaS platforms, and telecommunications operators have quantified these gains: compliance cost avoidance ($12M annually), agent productivity gains (7.5 FTE savings), customer retention improvements ($45M revenue protection), and conversion rate uplifts (35%) are not outliers—they are consistent outcomes across diverse domains.
Organizations should adopt a staged approach:
1. Foundation (Months 1–3): Deploy Traditional RAG for well-defined use cases (FAQ, technical documentation, internal knowledge bases). Measure baseline performance and establish operational patterns.
2. Transition (Months 4–6): Identify high-impact, high-complexity queries that Traditional RAG cannot serve well. Pilot Agentic RAG on these workflows using parallel orchestration patterns (fan-out/fan-in) for speed.
3. Scale (Months 7+): Expand Agentic RAG to cross-system queries and multi-step workflows. Adopt hierarchical orchestration where organizational complexity demands it. Integrate reflection loops and continuous learning.
Traditional RAG operators think of retrieval systems as "search engines that talk"—they retrieve and hand off to the LLM. Agentic RAG operators think of retrieval systems as "AI-driven knowledge workers"—they plan, reason, validate, and iterate.
This shift requires investment in:
But the returns—in automation depth, decision quality, regulatory confidence, and customer outcomes—justify the investment.
Enterprise AI is entering the era of agentic systems. Organizations that recognize Traditional RAG's limitations early and invest in Agentic RAG architectures will capture first-mover advantages in automation depth, customer experience, and operational efficiency. Those that treat Traditional RAG as a permanent solution risk finding themselves building brittle, hard-to-maintain systems that cannot evolve with business complexity.
The shift from static to adaptive is not optional—it is the next stage of enterprise AI maturity. The question is not whether to adopt Agentic RAG, but when, and how quickly teams can build the expertise and infrastructure to operate it at scale.
The technical foundations, real-world ROI patterns, orchestration frameworks, and production code patterns outlined in this blog provide a roadmap. The execution is yours.