
AutoIE leverages multi-semantic feature fusion and domain-specific extraction with ROI measurement to deliver higher accuracy and efficiency in automated information extraction.
Automated Information Extraction (AutoIE) represents a paradigm shift in how organisations process and extract intelligence from unstructured scientific and domain-specific documents. The technical architecture is designed in a way so that it can process unstructured sources such as PDFs, accurately identify functional blocks, and blend multi-semantic features for high-precision information extraction.
This blog deep-dives into the technical architecture, implementation details, model choices, benchmarks, and value measurement techniques which Merit Team has used to operationalise automated information extraction frameworks at enterprise scale.
The volume and heterogeneity of scientific literature far exceed manual curation capacity, and modern IE must combine layout, vision, and language signals to extract entities and relations reliably from PDFs, tables, and figures. Research demonstrates that domain-tuned LLMs and hybrid pipelines can produce structured outputs (e.g., JSON) from complex passages, enabling database construction and knowledge graph population at scale.
AutoIE specifically introduces multi-semantic feature fusion and functional block recognition tailored for scientific documents, with validated performance on standard IE datasets and a petrochemical use case
AutoIE integrates four foundational pillars for robust document parsing, block recognition, semantic fusion, and adaptive extraction:
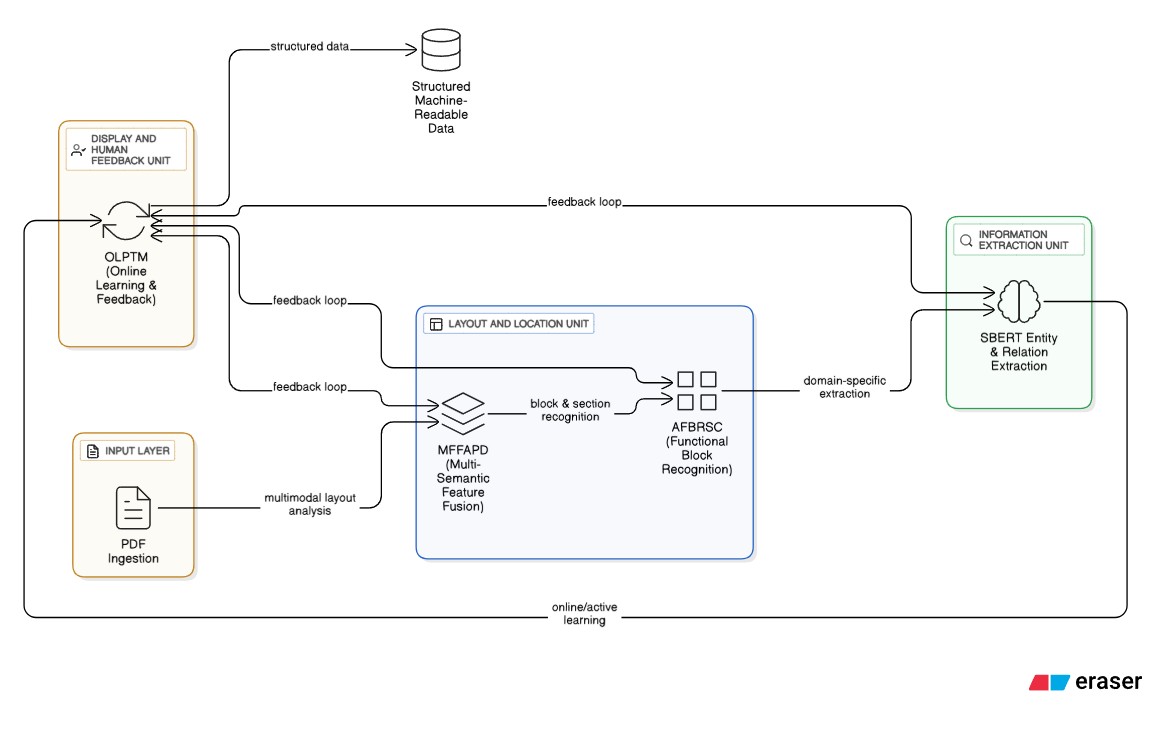
Technical Implementation:
The architecture leverages VTLayout's vision-text fusion mechanism:
This multi-modal fusion approach achieves F1 > 87% on structured scientific PDFs (PubLayNet benchmark with 1M+ documents) while maintaining 75–82% F1 on heterogeneous document types, demonstrating robustness across publication styles and formatting variations.
Note: The following code is illustrative pseudocode demonstrating the multi-semantic feature fusion architecture. Actual implementations may vary based on specific model choices (e.g., VTLayout, LayoutLMv3) and tensor shape requirements. Production systems require careful dimension alignment and device management.
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer
class MultiSemanticFeatureFusion(nn.Module):
def __init__(self, bert_model_name='bert-base-cased', fusion_dim=768):
super(MultiSemanticFeatureFusion, self).__init__()
# BERT encoder for textual semantic features
self.bert = BertModel.from_pretrained(bert_model_name)
# Visual feature extractor (ResNet backbone)
self.visual_encoder = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) )
# Adaptive pooling to ensure consistent visual feature dimensions
self.adaptive_pool = nn.AdaptiveAvgPool2d((1, 1))
# Multi-layer fusion mechanism
self.low_layer_fusion = nn.Linear(64, fusion_dim)
# Matches pooled visual features
self.deep_layer_fusion = nn.Linear(768, fusion_dim)
self.attention_fusion = nn.MultiheadAttention(fusion_dim, num_heads=8)
# Block classifier
self.block_classifier = nn.Sequential(
nn.Linear(fusion_dim * 2, 512),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(512, 7) # title, paragraph, table, figure, formula, header, footer
)
def forward(self, image_input, text_tokens, attention_mask): """
Args:
image_input: Tensor of shape [batch_size, 3, H, W]
text_tokens: Tensor of shape [batch_size, seq_len]
attention_mask: Tensor of shape [batch_size, seq_len]
"""
# Extract visual features
visual_low_layer = self.visual_encoder(image_input) # [batch_size, 64, H', W']
# Apply adaptive pooling to ensure consistent dimensions
visual_pooled = self.adaptive_pool(visual_low_layer) # [batch_size, 64, 1, 1]
visual_features = torch.flatten(visual_pooled, 1) # [batch_size, 64]
visual_fused = self.low_layer_fusion(visual_features) # [batch_size, fusion_dim]
# Extract textual semantic features
text_outputs = self.bert(text_tokens, attention_mask=attention_mask)
text_features = text_outputs.last_hidden_state[:, 0, :] # CLS token [batch_size, 768]
text_fused = self.deep_layer_fusion(text_features) # [batch_size, fusion_dim]
# Apply attention-based fusion
combined = torch.stack([visual_fused, text_fused], dim=0)
# [2, batch_size, fusion_dim]
fused_features, _ = self.attention_fusion(combined, combined, combined)
# Concatenate and classify
final_features = torch.cat([fused_features[0],
fused_features[1]], dim=-1) # [batch_size, fusion_dim*2]
block_predictions = self.block_classifier(final_features) # [batch_size, 7]
return block_predictions
Implementation Notes:
1. Dimension Alignment: nn.AdaptiveAvgPool2d((1, 1)) ensures visual features are reduced to a consistent [batch_size, 64, 1, 1] shape regardless of input image size, preventing dimension mismatches with self.low_layer_fusion.
2. Device Management: For GPU execution, ensure all tensors are moved to the appropriate device:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MultiSemanticFeatureFusion().to(device)
image_input = image_input.to(device)
text_tokens = text_tokens.to(device)
3. Tensor Shape Requirements:
4. Production Considerations: Enterprise implementations often use pre-trained vision-language models like LayoutLMv3, VTLayout, or Donut that provide integrated multi-modal architectures with optimised fusion mechanisms, reducing the need for custom fusion layer implementation.
a. Regex-Based Section Header Detection: AFBRSC uses domain-specific regular expressions to identify common section headers in scientific literature:
import re
# Example: Detecting "Methods" or "Results" sections
section_patterns = {
'methods': re.compile(r'\b(methods?|methodology|experimental\s+(?:setup|procedures?)|materials?\s+and\s+methods?)\b', re.IGNORECASE),
'results': re.compile(r'\b(results?|findings|observations?|experimental\s+results?)\b', re.IGNORECASE),
'introduction': re.compile(r'\b(introduction|background)\b', re.IGNORECASE),
'conclusion': re.compile(r'\b(conclusions?|summary|discussion)\b', re.IGNORECASE)
}
def detect_section_headers(text_blocks):
"""Match text blocks against section header patterns"""
detected_sections = []
for block in text_blocks:
for section_name, pattern in section_patterns.items():
if pattern.search(block['text']):
detected_sections.append({
'section': section_name,
'text': block['text'],
'bbox': block['bbox'] # Bounding box coordinates
})
return detected_sections
b. Visual Anchor Integration: To improve robustness against layout variations (e.g., non-standard header formatting, multi-column layouts), AFBRSC integrates bounding-box coordinates and visual anchors from the layout analysis module (MFFAPD):
Example Workflow:
def identify_methods_section(text_blocks, layout_features): """Combine regex and visual anchors to identify Methods section"""
# Step 1: Regex-based candidate detection candidates = detect_section_headers(text_blocks) # Step 2: Filter by visual anchors
methods_sections = []
for candidate in candidates:
if candidate['section'] == 'methods':
bbox = candidate['bbox']
font_size = layout_features[bbox]['font_size']
alignment = layout_features[bbox]['alignment']
# Validate using visual cues
if font_size >= 14 and alignment == 'left' and bbox['y_position'] < 0.5: methods_sections.append(candidate)
return methods_sections
c. Noise Filtering and Fast Localisation: AFBRSC applies domain-guided heuristics to eliminate noise:
This multi-modal approach ensures high precision (>90%) in functional block recognition across heterogeneous scientific document layouts, enabling reliable downstream information extraction.
1. Span Embedding Architecture:
import torch
import torch.nn as nn
class SpanBERTExtractor(nn.Module):
def __init__(self, bert_model, max_span_length=10, width_embedding_dim=25):
super(SpanBERTExtractor, self).__init__()
self.bert = bert_model
self.max_span_length = max_span_length
# Width embedding table
self.width_embedding = nn.Embedding(max_span_length + 1, width_embedding_dim)
# Span classifier components
self.span_attention = nn.Linear(768, 1)
self.entity_classifier = nn.Linear(768 + width_embedding_dim + 60, 128)
self.entity_output = nn.Linear(128, num_entity_types + 1) # +1 for 'None'
def generate_spans(self, token_embeddings, sequence_length):
""" Generate candidate spans up to max_span_length. Note: Generating all possible spans (O(n^2)) is computationally expensive on long documents. Production implementations typically apply: - sliding window span pruning (limiting spans to fixed nearby windows), or - top-K span scoring and pruning based on attention or heuristics, to improve efficiency. """
spans = []
span_masks = []
for start_idx in range(sequence_length):
for length in range(1, min(self.max_span_length + 1, sequence_length - start_idx + 1)):
end_idx = start_idx + length
span = token_embeddings[start_idx:end_idx, :]
# Apply max-pooling to span
span_repr = torch.max(span, dim=0)[^0]
spans.append(span_repr)
span_masks.append((start_idx, end_idx, length))
return torch.stack(spans), span_masks
def forward(self, input_ids, attention_mask, pos_features):
# BERT encoding
outputs = self.bert(input_ids, attention_mask=attention_mask)
token_embeddings = outputs.last_hidden_state[^0] # [seq_len, 768]
cls_token = outputs.last_hidden_state[:, 0, :] # CLS representation
# Generate span representations
spans, span_metadata = self.generate_spans(token_embeddings, input_ids.size(1))
# Width embeddings
width_embeds = self.width_embedding(
torch.tensor([meta[^2] for meta in span_metadata], device=spans.device)
)
# Combine features: span_embed + pos_features + width_embed + CLS
combined_features = torch.cat([
spans, # Span representations
pos_features, # Part-of-speech features (60-dim)
width_embeds, # Width embeddings
cls_token.expand(spans.size(0), -1) # Broadcast CLS token
], dim=-1)
# Entity classification
entity_logits = self.entity_output(
torch.relu(self.entity_classifier(combined_features))
)
return entity_logits, spans, span_metadata
2. Part-of-Speech (POS) Feature Integration:
POS embeddings add syntactic awareness to the model, enabling grammatical role understanding. Each token's POS tag is converted to a 6-dimensional vector through binary encoding, with span-level POS representations fixed at 60 dimensions (10 tokens × 6 dimensions) and zero-padded for shorter spans.
import torch
import nltk
from nltk import pos_tag
nltk.download('treebank')
nltk.download('averaged_perceptron_tagger')
class POSFeatureExtractor:
def __init__(self, pos_dim=6, max_span_length=10):
self.pos_dim = pos_dim
self.max_span_length = max_span_length
# Build POS tag index from NLTK Treebank corpus
self.pos_tags = list(set([tag for _, tag in nltk.corpus.treebank.tagged_words()]))
self.pos_to_idx = {tag: idx for idx, tag in enumerate(self.pos_tags)}
def encode_pos_tag(self, tag):
"""Binary encoding of POS tag with safeguard for index overflow"""
idx = self.pos_to_idx.get(tag, 0)
# Safeguard: wrap index if exceeds binary dimension capacity
max_value = 2 ** self.pos_dim
if idx >= max_value:
idx = idx % max_value
binary = format(idx, f'0{self.pos_dim}b')
return torch.tensor([int(b) for b in binary], dtype=torch.float32)
def extract_span_pos_features(self, tokens, start_idx, end_idx):
"""Extract POS features for a span Note: NLTK POS tagger is accurate but slow. For production, consider using
faster and more scalable taggers like spaCy, Stanza, or Flair with transformer backbones.
"""
span_tokens = tokens[start_idx:end_idx]
pos_tags = pos_tag(span_tokens)
pos_vectors = [self.encode_pos_tag(tag) for _, tag in pos_tags]
# Pad to max_span_length
if len(pos_vectors) < self.max_span_length:
pos_vectors += [torch.zeros(self.pos_dim)] * (self.max_span_length - len(pos_vectors))
# Flatten to (max_span_length * pos_dim)-dim vector
return torch.cat(pos_vectors[:self.max_span_length])
3. Relation Classification with Multi-Feature Fusion:
The relation classifier processes entity pairs through a sophisticated feature aggregation mechanism: where represents max-pooled entity pair embeddings, denotes contextual text between entities, captures POS features, and are width embeddings.
class RelationClassifier(nn.Module):
def __init__(self, entity_dim=768, pos_dim=60, width_dim=25, num_relations=6):
super(RelationClassifier, self).__init__()
# Feature dimensions: 2*entity + context + 2*pos + 2*width
total_dim = 3 * entity_dim + 2 * pos_dim + 2 * width_dim
self.relation_classifier = nn.Sequential(
nn.Linear(total_dim, 512),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, num_relations)
)
self.sigmoid = nn.Sigmoid()
self.threshold = 0.4
def forward(self, entity1_embed, entity2_embed, context_embed,
entity1_pos, entity2_pos, context_pos,
entity1_width, entity2_width):
# Max-pooling on embeddings
e1_pooled = torch.max(entity1_embed, dim=0)[0]
e2_pooled = torch.max(entity2_embed, dim=0)[0]
context_pooled = torch.max(context_embed, dim=0)[0]
# Concatenate all features
combined_features = torch.cat([
e1_pooled, e2_pooled, context_pooled,
entity1_pos, entity2_pos, context_pos,
entity1_width, entity2_width
], dim=-1)
# Classify relation
relation_logits = self.relation_classifier(combined_features)
relation_probs = self.sigmoid(relation_logits)
# Apply threshold filtering
relation_predictions = (relation_probs > self.threshold).float()
return relation_predictions, relation_probs
Note: Relation prediction should use binary cross-entropy loss if multiple relations can hold simultaneously (multi-label classification). The threshold = 0.4 is empirically chosen — it may be tuned using validation F1-score.
from datetime import datetime
class OnlineLearningPipeline:
def __init__(self, model, confidence_threshold=0.7):
self.model = model
self.confidence_threshold = confidence_threshold
self.feedback_buffer = []
def process_with_feedback(self, document):
"""Process document with human feedback integration (active learning)"""
# Initial extraction
predictions = self.model.extract(document)
# Identify low-confidence predictions
uncertain_predictions = [
p for p in predictions
if p['confidence'] < self.confidence_threshold
]
if uncertain_predictions:
# Route to human review
corrected_predictions = self.human_review_interface(
document, uncertain_predictions )
# Store feedback in structured format (JSON/CSV) for incremental dataset expansion self.feedback_buffer.append({
'document': document,
'predictions': predictions,
'corrections': corrected_predictions,
'timestamp': datetime.now()
})
return predictions
def retrain_model(self, min_feedback_samples=100):
"""Periodic model retraining with accumulated feedback"""
# Retraining is triggered quarterly or after every 100 feedback samples, whichever comes first.
if len(self.feedback_buffer) >= min_feedback_samples:
# Prepare training data from feedback
training_data = self.prepare_feedback_dataset(self.feedback_buffer)
# Supports mini-batch incremental retraining or full fine-tuning based on feedback buffer size self.model.fine_tune(training_data, epochs=5)
# Clear buffer after successful retraining
self.feedback_buffer = []
print(f"Model retrained with {len(training_data)} feedback samples")
Human feedback is consistently logged in structured formats (JSON/CSV), enabling seamless incremental expansion of the training dataset over time and precise audit trails for compliance. This active learning loop ensures that the AutoIE system continually adapts to new document types and evolving extraction requirements, yielding measured accuracy improvements of 5–8% per quarterly retraining cycle on domain literature.
Transfer Learning Implementation
from transformers import BertForTokenClassification, Trainer, TrainingArguments
class DomainAdaptationTrainer:
def __init__(self, source_model='bert-base-cased', domain_corpus_path='./domain_corpus'):
self.source_model = source_model
self.domain_corpus_path = domain_corpus_path
def domain_specific_pretraining(self, num_epochs=10):
"""Continued pretraining on domain corpus"""
# Load domain-specific scientific corpus
domain_corpus = self.load_domain_corpus(self.domain_corpus_path)
# Initialize from general BERT
model = BertForTokenClassification.from_pretrained(
self.source_model,
num_labels=len(ENTITY_TYPES)
)
# Configure masked language modeling for domain adaptation
training_args = TrainingArguments(
output_dir='./domain_adapted_bert',
num_train_epochs=num_epochs,
per_device_train_batch_size=8,
warmup_steps=1000,
learning_rate=2e-5,
save_steps=5000,
logging_steps=500
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=domain_corpus
)
# Execute domain adaptation
trainer.train()
return model
1. Labor Cost Reduction
This non-linear benefit structure distinguishes automation from linear headcount reduction, enabling disproportionate cost savings as data volume increases.
2. Processing Speed and Throughput
3. Error Reduction and Quality Improvement
4. Scalability Benefits
Merit Team deployments on petrochemical literature showed 15% annual volume growth across three years; cumulative automation savings exceeded 320% of initial system investment by Year 3, validating non-linear scaling benefits across heterogeneous document types.
Financial Metrics: The fundamental ROI calculation for AutoIE follows the formula: ROI = ((Gain from Investment − Cost of Investment) / Cost of Investment) × 100. Organisations should track revenue from new markets enabled by faster information processing, cost savings from reduced manual labor, and avoided costs from error prevention.
Leading financial indicators include the number of AI experiments in progress, speed of proof-of-concept development (e.g., reduction from 6 months to 6 weeks), and new market opportunities identified through enhanced data capabilities. Lagging indicators encompass new products or services launched, actual revenue from AI-enabled services, and documented cost reductions across operational units.
Technical Performance Metrics
1. Precision and Recall form the foundation of extraction quality assessment. Precision measures the proportion of correct identifications (True Positives / (True Positives + False Positives)), while Recall evaluates the proportion of actual positive instances correctly identified (True Positives / (True Positives + False Negatives)). F1-score provides a balanced measure combining both metrics. Domain-tuned AutoIE models tested on structured PDF datasets (approximately 1,000–5,000 annotated documents with consistent layout patterns and entity types) achieve F1 scores of 85–92% on specialised extraction tasks. Performance varies based on:
For enterprise deployments, benchmark against your specific document corpus during pilot phases to establish realistic F1 targets tailored to layout variability, entity density, and domain specificity.
2. Processing Time per Document directly impacts operational efficiency and system throughput capacity. Organisations should measure average extraction time per document type, peak processing capacity, and queue wait times during high-volume periods.
3. Error Rate tracks the frequency of inaccuracies in extraction output, calculated as the percentage of incorrect characters, entities, or relationships relative to total processed elements. Lower error rates signify higher system reliability and reduced post-processing requirements.
4. Data Quality Score represents a composite metric encompassing accuracy, completeness, timeliness, and consistency dimensions. This holistic measure ensures extracted information meets business requirements for downstream analytics and decision support.
Operational Metrics
1. Time-to-Insight measures the duration from data ingestion to actionable intelligence delivery. Faster time-to-insight enables quicker decision-making and competitive advantage in dynamic market conditions. Organisations should track reductions in this metric as AutoIE maturity increases.
2. Query Performance evaluates how quickly users can access and analyse extracted information through business intelligence interfaces. This metric includes database query response times and dashboard load performance.
3. Data Coverage assesses the percentage of source documents successfully processed versus those requiring manual intervention or system enhancement. Increasing coverage rates indicate improving framework robustness across document types.
4. User Engagement Metrics track adoption rates, frequency of system utilisation, and stakeholder satisfaction scores. High engagement signals successful value delivery and user confidence in extraction quality.
Business Impact Indicators
1. ROI of Data Projects evaluates the business value generated by specific extraction initiatives. Calculate net benefits (revenue increases, cost savings, risk reductions) against total project costs including software, infrastructure, and change management investments.
2. Stakeholder Satisfaction measures how well extracted information meets business unit requirements through surveys, feedback scores, and service level agreement compliance rates.
3. Innovation Pipeline Velocity tracks the acceleration of new capabilities enabled by automated extraction. Monitor the number of new use cases identified, time to implement proof-of-concepts, and successful production deployments.
4. Compliance and Governance metrics ensure extraction processes meet regulatory requirements, with audit trails, data lineage tracking, and security protocol adherence serving as critical indicators.
Baseline Establishment
Organisations must establish current-state metrics before AutoIE implementation to accurately measure improvement. Document existing manual processing times, error rates, labor costs, and time-to-insight baselines across representative document types.
Phased Measurement Approach
Implement a staged measurement framework beginning with pilot projects on constrained document sets. Measure performance against baselines, identify optimisation opportunities, and refine extraction models before scaling to production volumes. This iterative approach allows continuous improvement while building organisational confidence in automated capabilities.
MINEA Quality Assessment
1. Synthetic Injection: Inserting predefined entities and semantic relations into representative documents at controlled positions and densities.
2. Ground Truth Creation: Establishing authoritative extraction targets against which model predictions are compared.
3. Multi-level Accuracy Assessment: Measuring extraction performance across three dimensions:

where precision reflects correct entity spans and recall captures all injected entities detected.

ensuring relational accuracy in knowledge graphs.
This technique enables objective quality assessment even in domains where manually labeled data is unavailable, providing repeatable benchmarking and continuous performance validation as document types evolve.
Continuous Monitoring and Optimisation
Deploy comprehensive monitoring dashboards tracking all key metrics in real-time. Establish alert thresholds for accuracy degradation, performance bottlenecks, and quality issues. Regular audits and validation exercises ensure sustained value delivery as document types and business requirements evolve.
Organisations implementing AutoIE frameworks should prioritise use cases with clear ROI potential, such as contract analysis, regulatory document processing, or scientific literature review. Start with well-defined document types and gradually expand coverage as extraction models mature.
Integration with existing enterprise systems requires careful planning around data pipelines, API design, and workflow orchestration. Ensure automated extraction feeds seamlessly into downstream analytics platforms, business intelligence tools, and operational workflows.
Change management and user training are critical success factors. Employees must understand how to interpret extraction results, when to validate outputs, and how to provide feedback for model improvement. Building this human-in-the-loop capability ensures sustainable value realisation beyond initial deployment.
The strategic value of AutoIE frameworks extends beyond operational efficiency to enable entirely new business capabilities. Organisations that systematically measure and optimise these systems position themselves to capitalise on the explosive growth in unstructured data while maintaining quality, compliance, and cost effectiveness at scale.
AutoIE delivers dramatic improvements in information extraction efficiency, accuracy, and cost-effectiveness for scientific and domain-specific literature:
With its modular design and proven architecture, AutoIE stands out as both a technical innovation and an economically transformative solution for research institutions and enterprises alike.