As restrictions and limitations on data usage get ever tighter and advertising spend more scrutinised for return on investment, there has been an increasing focus on the data you have within your database or CRM.
Whatever your go-to-market strategy, your database of contacts and companies is a key component of success – not just in terms of return on investment, but on efficiency and productivity of your sales and marketing teams. It poses a risk to businesses to get it wrong – it can cause friction between teams or it can be brand damaging if you create a poor first impression with potential customers. Get it really wrong and you can impact your reputation – both your market reputation and your martech reputation, such as email deliverability.
So why are so many companies struggling with getting the foundations in place, and keeping them strong? There are many common challenges with marketing data:
Completeness
Maybe you have a high volume of data, but there is lots of missing information – empty fields staring back at you – which makes it difficult to segment your data. Too many contacts fall between the gaps into the dreaded ‘default’ segment, which negates all the hard work that you’ve done in creating bespoke and targeted messaging to different cohorts.
By … default, this means that messaging has to be more generic and won’t resonate. This limits your click through rates, or conversions and makes portions of your database ineffective. And all because you’re missing a job title value.
A finely-tuned mix of automation, AI and human input is often the best approach. Methodically working through the fields that are critical to your top automations, and working with data partners to drive your completeness towards 100% can be the fastest way to see a direct impact on your send sizes and effectiveness of those campaigns.

Accuracy
Maybe your database is reasonably complete, but how many times have you eye-balled your data before a send and your heart drops because you can see nonsensical or inaccurate information? There are two typical ways you end up with inaccurate data.
Firstly, user generated. As frustrating as it is, humans – your prospects and customers – are often the key source of inaccurate information. A typo in their company name which means it doesn’t match your company filters, or perhaps Unitd Kingdom with that critical ‘e’ missing which means the contact doesn’t get picked up in the right country filter.
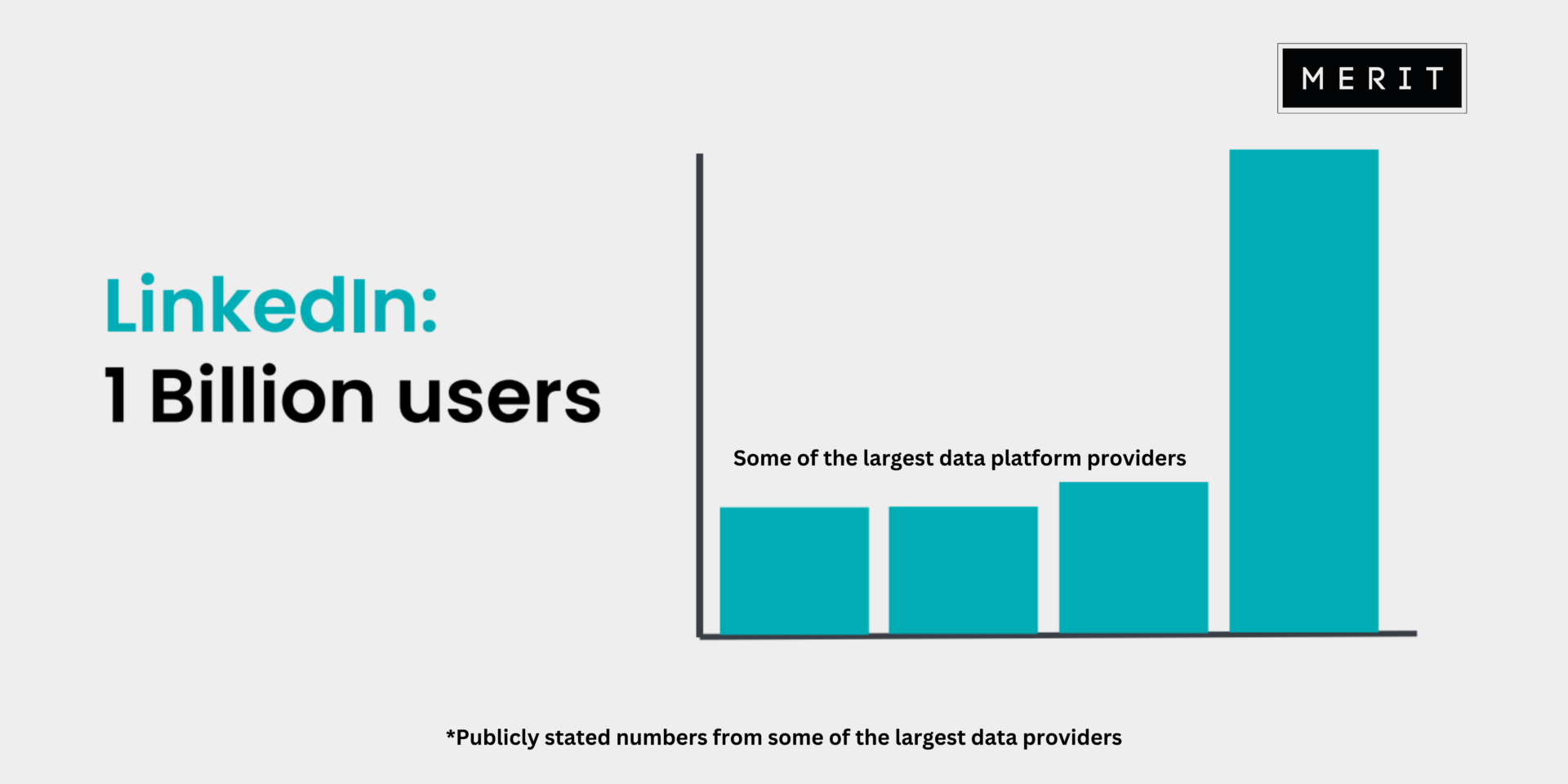
Second, database generated. There are platforms available that scrape data from the internet to populate a library of contacts. These rely largely on volume but none come close to a platform such as LinkedIn which has 1 billion users. With some of the largest data providers making claims of 200-300 million contacts in their databases, this means that approximately 66% of people are missing. This can be particularly apparent in some industries which are less represented on LinkedIn. But potentially the biggest drawback is how this data is often pulled. It can inaccurately look for keywords anywhere within the LinkedIn profile and therefore the data you are sourcing represents a job title from the past. How many times are you contacted by an enthusiastic sales person via LinkedIn referencing a job you haven’t worked in for three years?
The data is tantalisingly at your fingertips but it won’t end up in your send. And worse of all, the mistakes can be so unique that there are a countless number of variations which can make it very time consuming, or nearly impossible, to fix on a case by case basis. This can be tackled by identifying those that don’t fall into the segments as you would expect e.g. don’t qualify for a ‘known’ country, and revalidating their information en masse.
Relevant
Be it through sub-optimal data research in the past, gamification of KPIs from sales teams to add leads or a uplift in your content marketing efforts attracting a range of users, there’s lots of reasons that the relevancy of your database may not be a match for your ideal client personas (ICP) and account-based marketing (ABM) strategies.
Relevancy is relative to your type of business, but on the contact level key traits most likely include being the decision maker or being a key influencer. Imagine the sales process to help you construct that decision making unit (DMU). There may be an introductory call with a ‘gatekeeper’ who is going to collect key information on behalf of others or for a procurement process. Then, on follow up sales calls, who are the other people that would be likely to join? That’s your DMU.
Now compare those job titles to your database.
Similarly for company records, by looking at the variables which your current/ past customers have in common, how many other companies in your database match that? Maybe it’s based on turnover, age of business, number of employees, or their technology landscape but there will be strong indications of the type of companies that work with you and bring in the largest yield.
It’s not to dismiss these records, many may show their returns in the future – the junior contacts downloading content now will be leading business’ one day. But in the meantime, increasing the proportion of the records, both contact and company, that are most relevant to you today is important to prioritise.
This can be a complex process when there are multiple variables to consider. Maybe certain job titles are only relevant from certain industries, or are only likely to exist in companies of certain sizes. Crafting this brief is the first step to working successfully with partners that can give you a bespoke approach to data research that works with your market’s nuances.

Recent
Recency is intertwined with both accuracy and relevancy above. Data churns approximately every 18-36 months. This makes sense when you think about the typical timelines over which your customers are likely to take on different responsibilities within their company, or move roles. Therefore your database is constantly fluxing in accuracy and relevancy.
If the record moves company, it’s likely you will become aware because their email address will become invalid. But it’s not uncommon that a mailbox is kept live for a few months to field incoming enquiries. You might only know three months after that person already announced the change on LinkedIn.
Even with the invalid email ‘big red flag’, so many companies continue to sit on that dead data. And the volume only gets bigger the longer it goes unresolved. This is costing companies direct money as those contacts still count towards your database volume in your marketing automation platform.
You’re also missing out on new opportunities. What if you could find out where that person moved to? After all, the chances are strong that they have moved to a similar role in a similar company. And what about knowing who filled their vacancy? They were your target before, so they should be your target still.
Oppositely, if someone moves within their company to a new role, there’s no invalid email and that often means no indication. You continue to email, maybe they unsubscribe, maybe they simply keep deleting, and you’re none the wiser. Unless you’re looking for a change in behaviour to your marketing efforts e.g. looking for contacts that have not clicked in the last 3 months but did regularly before that, you’re unlikely to ever find out.
More campaigns are compromised. More money is wasted. More opportunities are missed.
Large database platforms may only be scraping data every 6 months, sometimes longer, which means these changes are also not reflected for a significant period of time. Some of the leading platforms have updated less than 20% of their contacts in the last year.

Gaps
Landscape mapping should be a regular exercise – new companies enter the market, perhaps product development brings different company types into your space, and companies change their internal structures bringing new roles into your addressable market.
For this reason, regular data research is advisable, even though it doesn’t always strike as the most pressing marketing job when emails need to go out and sales need more leads.
Invest some time into defining the fields or database inputs which contribute to how you find your key cohorts. This could be something such as job function, or company type. Build lists within your marketing automation platform to find all of the contacts or companies that match that criteria. Now compare that to what you think the addressable market is.
You may have some pleasant surprises for areas you look very strong, you may have a few less pleasant surprises.
A series of one off projects will help to fill the biggest gaps. After that, a quarterly review of the volume of the lists is advisable. Once they are set up, this is a very quick job but can be vital in spotting areas where your database gap is widening again.

The mysterious …
Coming nearly full circle to the drawbacks of user-generated data from forms on your website, or registrations to your events.
Your prospects are in a rush, and your database hygiene is the last thing on their mind. So, for speed, a job title of merely ‘Director’ or ‘Manager’ suffices. You’re left wondering ‘Director of what?’. It gives you an indication of seniority but you have no idea of the department or their job function within the company. It leaves you wondering what their interest is in your content or products and even more at a loss as to how to communicate with them.
Another blow to your targeting message efforts. The dreaded default segment strikes again.
Enriching your database with more full and informative values can supercharge your automations and segments. Of many potential data research efforts, this is a particularly sound one for getting the return on your investment. They have given a behavioural indication of a strong interest in your services or products and you can refine your brief to those that seem to have the right seniority or another trait that you’ve gleaned. These contacts have a good chance of being nurtured further along the customer journey.
The top solution to your marketing data challenges
While the challenges can seem numerous and amongst the day-to-day, wading through your data can feel about as appealing as wading through treacle, there are solutions.
Working with a partner like Merit, is exactly that, working with a partner. We’re a data team, not a product. The delivery aim is clear – reliable, high-quality data that’s simple for you to use in your marketing campaigns. The perfect balance of automation, AI and human hands means we can deliver maximum data completeness. However complex the data brief, we can get you the ‘if only I knew’ data which you think will light up your campaigns. We’ll help you craft briefs, with built-in prioritisation, logic and limits so you get the data that matches your needs and nothing else. No technology platforms to learn, or limitations in functionality. We’re as flexible as you can be creative.
And most importantly, there’s no Merit database. There’s only yours.

Related Case Studies
-
01 /
Sales and Marketing Data Analysis and Build for Increased Market Share
A leading provider of insights, business intelligence, and worldwide B2B events organiser wanted to understand their market share/penetration in the global market for six of their core target industry sectors. This challenge was apparent due to the client not having relevant tech tools or the resources to source and analyse data.
-
02 /
Enhanced Audience Data Accuracy for a High Marketing Campaign RoI
An international market leader in exhibitions within the learning, healthcare, technology and veterinary sectors.